サーバーのメトリクスを可視化する(Prometheus、Grafana、Node Exporter、cAdvisor)
サーバーのメトリクスを可視化して確認できるようにしたい。
PrometheusとGrafanaでやってみる。
環境
- OS:RockyLinux8.6
- Prometheus:v2.37.1
- Grafana:9.1.6
- Node Exporter:1.4.0
- cAdvisor:0.45.0
構成図
今回構築する環境の構成イメージは以下の通り。
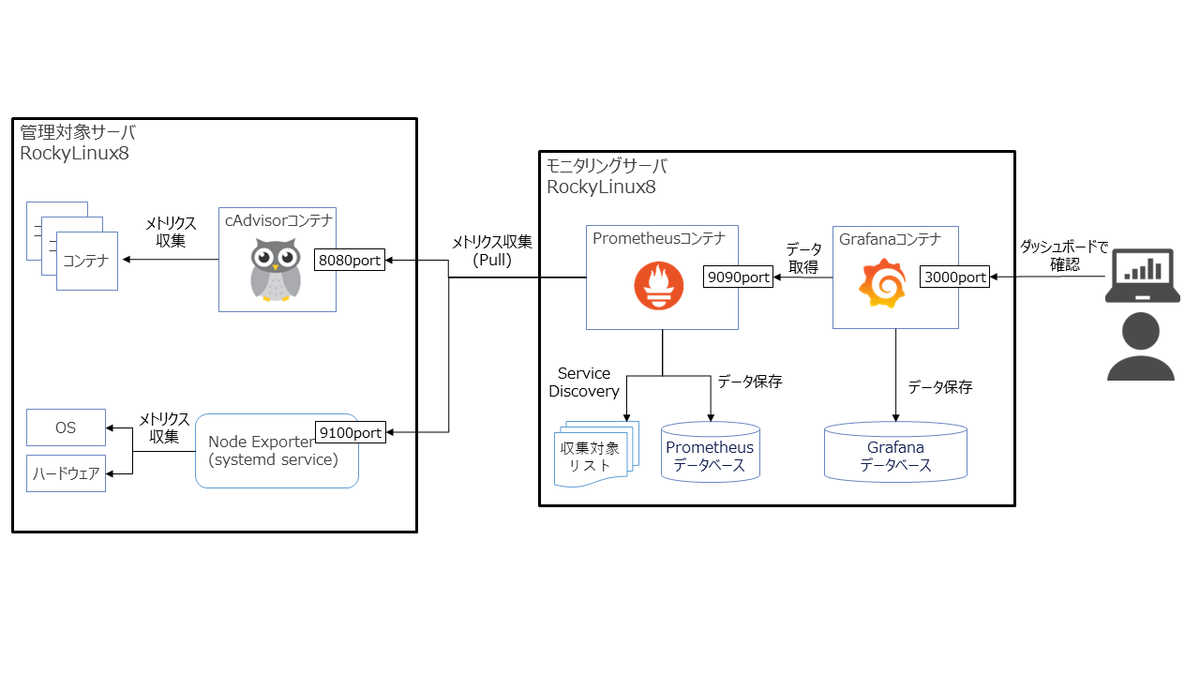
- 出来るだけお手軽かつ、他の環境にもすぐに再現できる構成にしたいので、Prometheus、GrafanaはDockerコンテナで構成する。
- ハードウェア・OSの標準的なメトリクスの取得は、Prometheusの代表的なexporterであるNode Exporterで収集する。
- コンテナもよく使うので、コンテナのメトリクスも収集したい。cAdvisorで収集する。
※使用するソフトウェア・ツール一覧 prometheus.io
モニタリングサーバを構築する
DockerとDocker Composeインストール
こちらを参照し、Dockerをインストールする
# dnf remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
# dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
# dnf -y install docker-ce docker-ce-cli containerd.io
# systemctl start docker
# docker info | grep Version
Server Version: 20.10.18
Cgroup Version: 1
Kernel Version: 5.18.9-1.el8.elrepo.x86_64
# systemctl enable docker
# docker run hello-world
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
2db29710123e: Pull complete
Digest: sha256:62af9efd515a25f84961b70f973a798d2eca956b1b2b026d0a4a63a3b0b6a3f2
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
こちらを参照し、Docker Composeをインストールする
# dnf -y update # dnf -y install docker-compose-plugin # docker compose version Docker Compose version v2.10.2
PrometeusとGrafanaを起動する
PrometheusとGrafanaをコンテナで起動する方法はそれぞれ以下に記載されている。
今回はコンテナをDocker Composeで管理したいので、上記ページを参考にcomposeファイルを書いてみる。
composeファイルの書式は公式ドキュメントに従う。
composeファイル配置用ディレクトリを作成する(どこでもよい)
# mkdir -p /opt/docker/monitoring
composeファイルを作成する
# vim /opt/docker/monitoring/docker-compose.yml
services:
prometheus:
image: prom/prometheus:v2.37.1
container_name: prometheus-2.37.1
ports:
- "9090:9090"
volumes:
- /opt/docker/monitoring/prometheus/etc:/etc/prometheus # prometheusの設定ファイル置き場
- /opt/docker/monitoring/prometheus/data:/prometheus # prometheusのデータ保管場所
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--storage.tsdb.retention.time=31d' # ローカルストレージへのメトリクス保存期間
- '--web.console.libraries=/usr/share/prometheus/console_libraries'
- '--web.console.templates=/usr/share/prometheus/consoles'
grafana:
image: grafana/grafana-oss:9.1.6
container_name: grafana-oss-9.1.6
ports:
- "3000:3000"
volumes:
- /opt/docker/monitoring/grafana/data:/var/lib/grafana # Grafanaのデータ保管場所
→composeファイル記載時のポイントは以下。
- ローカルストレージへのメトリクス保存期間はデフォルトだと15日間。短いので、今回は31日間に変更してみた。
Prometheusのストレージに関するオプションはこちらを参照。 - コンテナ内のデータはコンテナ終了時に消えてしまうため、永続化したいファイルの配置ディレクトリは、volumesでホストのストレージをマウントしている。
- Prometheusのデータ保管場所は「/prometheus」だが、公式ドキュメントにはこの記載が見当たらなかった。
最終的にprom/prometheusイメージのDockerfileを確認して特定した。
次に、Prometheusコンテナのvolumes用ディレクトリを作成する。
ディレクトリの所有ユーザ/グループはコンテナの実行ユーザ/グループと揃える。
# mkdir -p /opt/docker/monitoring/prometheus/etc # mkdir /opt/docker/monitoring/prometheus/data # chown 65534:65534 /opt/docker/monitoring/prometheus/* # ls -l /opt/docker/monitoring/prometheus 合計 4 drwxr-xr-x 8 nobody nobody 4096 10月 4 08:19 data drwxr-xr-x 3 nobody nobody 70 10月 3 15:39 etc
※所有ユーザ/グループの設定が誤っている場合、以下のエラーとなりコンテナの起動に失敗する。
# docker logs prometheus-2.37.1 (略) ts=2022-10-04T07:51:22.656Z caller=query_logger.go:91 level=error component=activeQueryTracker msg="Error opening query log file" file=/prometheus/queries.active err="open /prometheus/queries.active: permission denied" panic: Unable to create mmap-ed active query log
Prometheusコンテナの実行ユーザ/グループについてはドキュメントに記載がなかったので、以下のように確認した。 UID、GID共に65534だと分かる。
# docker run -it --rm --entrypoint sh prom/prometheus:v2.37.1 /prometheus $ id uid=65534(nobody) gid=65534(nobody) groups=65534(nobody)
Grafanaコンテナのvolumes用ディレクトリも同様に作成し、所有ユーザ/グループを設定する。
# mkdir -p /opt/docker/monitoring/grafana/data # chown 472:0 /opt/docker/monitoring/grafana/data # ls -l /opt/docker/monitoring/grafana 合計 0 drwxr-xr-x 2 472 root 6 10月 4 07:51 data
※所有ユーザ/グループの設定が誤っている場合、以下のエラーとなりコンテナの起動に失敗する。
# docker logs grafana-oss-9.1.6 GF_PATHS_DATA='/var/lib/grafana' is not writable. You may have issues with file permissions, more information here: http://docs.grafana.org/installation/docker/#migrate-to-v51-or-later mkdir: can't create directory '/var/lib/grafana/plugins': Permission denied
Grafanaコンテナの実行ユーザ/グループについてはGrafanaドキュメントのここによると、UIDは472、GIDは0。
実際のコンテナでも念のため確認した。ドキュメント通り。
# docker run -it --rm --entrypoint sh grafana/grafana-oss:9.1.6 /usr/share/grafana $ id uid=472(grafana) gid=0(root) groups=0(root)
Prometheusの設定ファイル(prometheus.yml)を作成する。
内容は公式ドキュメントの「GETTING STARTED」を参考にした。
# vim /opt/docker/monitoring/prometheus/prometheus.yml
global:
scrape_interval: 15s # Prometheusがtargetからメトリクスを取得する間隔
external_labels:
monitor: 'codelab-monitor'
scrape_configs:
# Prometheus
- job_name: 'prometheus'
scrape_interval: 5s # global.scrape_intervalを上書き
static_configs:
- targets: ['localhost:9090']
Prometheusコンテナ、Grafanaコンテナを起動する。
# docker compose -f /opt/docker/monitoring/docker-compose.yml -p monitoring up -d # docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES e70494ddaeb8 grafana/grafana-oss:9.1.6 "/run.sh" About a minute ago Up About a minute 0.0.0.0:3000->3000/tcp, :::3000->3000/tcp grafana-oss-9.1.6 23583f1fe8ce prom/prometheus:v2.37.1 "/bin/prometheus --c…" About a minute ago Up About a minute 0.0.0.0:9090->9090/tcp, :::9090->9090/tcp prometheus-2.37.1
動作確認と初期設定
ブラウザで「http://{モニタリングサーバのIP}:9090」に接続し、Prometheusの画面が表示されることを確認する。

Prometheusが収集したメトリクスをグラフ化して参照してみる。
prometheus.ymlでPrometheus自身のメトリクス収集を設定してあるので、試しにPrometheusのローカルストレージのチャンクの 1 秒あたりのレートをグラフ化してみる。
Graphタブを選択して、「rate(prometheus_tsdb_head_chunks_created_total[1m])」と入力してexecuteをクリックすると、以下のようにグラフが表示される。

Prometheusが正常に動作していることが確認できたので、次にGrafanaでPrometheusが収集したメトリクスをグラフ化してみる。
ブラウザで「http://{モニタリングサーバのIP}:3000」に接続し、Grafanaのログイン画面が表示されることを確認する。

username、password共に「admin」と入力して「Log in」をクリックし、ログインできることを確認する。

Prometheusが収集したメトリクスにアクセスするには、Grafanaにデータソースとして追加する必要がある。
Grafanaで「Configuration(画面左の歯車マーク)」→「Data sources」→「Add data source」→「Prometheus」と選択する。

上記のように、設定値の入力画面になる。設定値の詳細は以下を参照のこと。 Prometheus data source | Grafana documentation
URLに「http://prometheus-2.37.1:9090」と入力し、画面下部の「Save & test」をクリックする。
以下のように、「Data source is working」と表示されれば、正常にデータソースに追加出来ている。

データソースに追加できたので、試しにグラフ化してみる。
「Dashboards(画面左の四角マーク)」→「+ New dashboard」→「Add a new panel」と進む。
画面下のMetrics browserに、先ほどPrometheusでグラフ表示した際と同様、「rate(prometheus_tsdb_head_chunks_created_total[1m])」と入力して「Run queris」をクリックする。
以下のようにグラフが表示される。

モニタリングサーバにて、Prometheusでメトリクス収集し、Grafanaでそれをグラフ化できることを確認できた。
次は管理対象のサーバからメトリクス収集する設定を行う。
Node Exporterでハードウェア・OSのメトリクスを収集する
以下を参考に、Node Exporterを使って管理対象サーバのハードウェア・OSメトリクスを収集してみる。
prometheus.io
GitHub - prometheus/node_exporter: Exporter for machine metrics
Node Exporterのインストール・起動
管理対象サーバにtarballでNode Exporterをインストールする。
tarballはここからダウンロードできる。
# mkdir /opt/prometheus # cd /opt/prometheus # wget https://github.com/prometheus/node_exporter/releases/download/v1.4.0/node_exporter-1.4.0.linux-amd64.tar.gz # tar zxf node_exporter-1.4.0.linux-amd64.tar.gz # ls -l node_exporter-1.4.0.linux-amd64 合計 19200 -rw-r--r--. 1 3434 3434 11357 9月 26 12:39 LICENSE -rw-r--r--. 1 3434 3434 463 9月 26 12:39 NOTICE -rwxr-xr-x. 1 3434 3434 19640886 9月 26 12:33 node_exporter # ln -s /opt/prometheus/node_exporter-1.4.0.linux-amd64/node_exporter /usr/local/bin/node_exporter # ls -l /usr/local/bin/node_exporter lrwxrwxrwx. 1 root root 61 10月 11 07:08 /usr/local/bin/node_exporter -> /opt/prometheus/node_exporter-1.4.0.linux-amd64/node_exporter # rm -rf node_exporter-1.4.0.linux-amd64.tar.gz
Node Exporterを起動する。
# nohup node_exporter & # ps aux | grep node_exporter | grep -v grep root 14381 0.0 1.2 724844 22596 pts/0 Sl 11:53 0:00 ./node_exporter
以下のように、Node Exporterが公開しているメトリクスを「http://localhost:9100/metrics」で確認できる。
# curl -s http://localhost:9100/metrics | head
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 3.1201e-05
go_gc_duration_seconds{quantile="0.25"} 6.0298e-05
go_gc_duration_seconds{quantile="0.5"} 8.5714e-05
go_gc_duration_seconds{quantile="0.75"} 0.000121806
go_gc_duration_seconds{quantile="1"} 0.003530947
go_gc_duration_seconds_sum 2.909751902
go_gc_duration_seconds_count 10781
# HELP go_goroutines Number of goroutines that currently exist.
Prometheusの設定変更
Node Exporterからメトリクスを収集するよう、Prometheusに設定をする。
モニタリングサーバのprometheus.ymlに以下のように追記をする。
# vim /opt/docker/monitoring/prometheus/etc/prometheus.yml
global:
scrape_interval: 15s # Prometheusがtargetからメトリクスを取得する間隔
external_labels:
monitor: 'codelab-monitor'
scrape_configs:
# Prometheus
- job_name: 'prometheus'
scrape_interval: 5s # global.scrape_intervalを上書き
static_configs:
- targets: ['localhost:9090']
# Node Exporter
- job_name: node
file_sd_configs:
- refresh_interval: 30s # targetsファイルの読み込み間隔
files: # targetsファイルを記載
- /etc/prometheus/sd_files/node_targets.yml
# vim /opt/docker/monitoring/prometheus/etc/sd_files/node_targets.yml
- targets:
→メトリクス収集対象は、「job_name: 'prometheus'」に設定しているように「static_configs」に固定的に記載すると、設定変更時にPrometheusの再起動orリロードが必要になる。
Prometheusには他にファイルベースのServiceDiscovery機能がある。
「file_sd_configs」に設定したtargetsファイルに収集対象を記載することで、定期的(デフォルトは5分間隔)にファイルが読み込まれ、記載内容が自動反映される挙動となるため、これを使ってみる。
ちなみに、今回は設定変更がすぐ反映されるよう、refresh_intervalを設定することで読み込み間隔を30秒に短縮している。
※targetsファイルの書式や、refresh_intervalについてはこちらを参照。
Prometheusをリロードして、prometheus.ymlの変更を反映する。
(リロード方法はこれを参考にした。)
# docker exec -it prometheus-2.37.1 killall -HUP prometheus # docker logs prometheus-2.37.1 (略) ts=2022-10-01T12:38:36.093Z caller=main.go:1177 level=info msg="Loading configuration file" filename=/etc/prometheus/prometheus.yml ts=2022-10-01T12:38:36.093Z caller=main.go:1214 level=info msg="Completed loading of configuration file" filename=/etc/prometheus/prometheus.yml totalDuration=490.179μs db_storage=1.123μs remote_storage=1.402μs web_handler=592ns query_engine=1.256μs scrape=81.433μs scrape_sd=40.833μs notify=1.098μs notify_sd=1.645μs rules=1.487μs tracing=3.89μs
PrometheusのWeb画面で「Status」→「Targets」と選択すると、以下のように収集対象を確認できる。
node_targets.ymlに収集対象の情報を記載していないため、Node Exporterはまだ収集対象になっていない。

targetsファイルを編集する。JSON、YAMLで記載できるが今回はYAMLで記載した。
# vim /opt/docker/monitoring/prometheus/etc/sd_files/node_targets.yml
- targets:
- {管理対象サーバのIP}:9100
labels:
service: node # Node Exporterだと分かるように、Labelを付けておく。
編集後30秒以内には、ファイルベースのServiceDiscovery機能により管理対象サーバのNode ExporterがPrometheusのTargetsに追加される。

Grafanaのダッシュボードを作成
Grafanaでダッシュボードを作成するが、一から作成するのは手間がかかる。
Grafanaにはダッシュボードをインポートする機能があるので、インポートして作成する。
ダッシュボードは、以下サイトで公開されている。
インポートしたいダッシュボードのIDを控えておく。
grafana.com
今回は「Node Exporter Full」というダッシュボードを使わせていただく。
GrafanaのWeb画面で「Dashboards(画面左の四角マーク)」→「+ Import」と進み、「Import via grafana.com」に控えていたダッシュボードのIDを入力し、「Load」をクリックする。
以下のようにダッシュボードの情報が表示されるので、「Prometheus」にDataSourceに追加したPrometheusを選択し、「Import」をクリックする。

以下のように、インポートしたダッシュボードが表示される。
あとは必要に応じてカスタマイズしていけばOK。

Node Exporterの自動起動設定
Node Exporterをtarballでインストールした場合、そのままだと自動起動設定できないので、systemd service化する必要がある。
以下を参考にやってみる。
node_exporter/examples/systemd at master · prometheus/node_exporter · GitHub
Installing node_exporter as systemd serivice · GitHub
Node Exporter用のユーザを作成し、必要な権限設定・ディレクトリ作成を行う。
Node Exporter実行用のユーザを作成 # useradd --system --shell /sbin/nologin node_exporter ユーザが作成されたことを確認 # cat /etc/group | grep node_exporter node_exporter:x:985: Node Exporterの実行ファイルの権限を変更 # chown node_exporter:node_exporter /usr/local/bin/node_exporter リンク先を確認(シンボリックリンク自体のパーミッションに意味はないので気にしなくてよい。) # ls -l /usr/local/bin/node_exporter lrwxrwxrwx. 1 root root 61 10月 11 07:08 /usr/local/bin/node_exporter -> /opt/prometheus/node_exporter-1.4.0.linux-amd64/node_exporter Node Exporterの実行ファイルの権限を確認 # ls -l /opt/prometheus/node_exporter-1.4.0.linux-amd64/node_exporter -rwxr-xr-x. 1 node_exporter node_exporter 19640886 9月 26 12:33 /opt/prometheus/node_exporter-1.4.0.linux-amd64/node_exporter Node ExporterのTEXTFILE COLLECTOR用ディレクトリを作成 # mkdir -p /var/lib/node_exporter/textfile_collector TEXTFILE COLLECTOR用ディレクトリの権限設定 # chown node_exporter:node_exporter /var/lib/node_exporter/textfile_collector TEXTFILE COLLECTOR用ディレクトリの権限確認 # ll /var/lib/node_exporter 合計 0 drwxr-xr-x. 2 node_exporter node_exporter 6 10月 2 14:54 textfile_collector
serviceの定義ファイルを作成する。
# cat <<EOF > /etc/systemd/system/node_exporter.service [Unit] Description=Node Exporter [Service] User=node_exporter EnvironmentFile=-/etc/sysconfig/node_exporter ExecStart=/usr/local/bin/node_exporter \$OPTIONS [Install] WantedBy=multi-user.target EOF # echo "OPTIONS=\"--collector.textfile.directory /var/lib/node_exporter/textfile_collector\"" > /etc/sysconfig/node_exporter
serviceとして登録する。
# systemctl daemon-reload # systemctl enable --now node_exporter Created symlink /etc/systemd/system/multi-user.target.wants/node_exporter.service → /etc/systemd/system/node_exporter.service.
node_exporterが正常に起動していることを確認する。「Active: active (running)」となっていればOK。
これで、サーバを再起動しても自動的にnode_exporterが起動する。
# systemctl status node_exporter
● node_exporter.service - Node Exporter
Loaded: loaded (/etc/systemd/system/node_exporter.service; enabled; vendor preset: disabled)
Active: active (running) since Tue 2022-10-11 07:18:07 UTC; 33s ago
Main PID: 421117 (node_exporter)
Tasks: 5 (limit: 10992)
Memory: 8.0M
CGroup: /system.slice/node_exporter.service
mq421117 /usr/local/bin/node_exporter --collector.textfile.directory /var/lib/node_exporter/textfile_collector
10月 11 07:18:07 ip-10-0-102-254.ap-northeast-1.compute.internalmydomain.local node_exporter[421117]: ts=2022-10-11T07:18:07.479Z caller=node_exporter.go:115 level=info collector=thermal_zone
10月 11 07:18:07 ip-10-0-102-254.ap-northeast-1.compute.internalmydomain.local node_exporter[421117]: ts=2022-10-11T07:18:07.479Z caller=node_exporter.go:115 level=info collector=time
10月 11 07:18:07 ip-10-0-102-254.ap-northeast-1.compute.internalmydomain.local node_exporter[421117]: ts=2022-10-11T07:18:07.479Z caller=node_exporter.go:115 level=info collector=timex
10月 11 07:18:07 ip-10-0-102-254.ap-northeast-1.compute.internalmydomain.local node_exporter[421117]: ts=2022-10-11T07:18:07.479Z caller=node_exporter.go:115 level=info collector=udp_queues
10月 11 07:18:07 ip-10-0-102-254.ap-northeast-1.compute.internalmydomain.local node_exporter[421117]: ts=2022-10-11T07:18:07.479Z caller=node_exporter.go:115 level=info collector=uname
10月 11 07:18:07 ip-10-0-102-254.ap-northeast-1.compute.internalmydomain.local node_exporter[421117]: ts=2022-10-11T07:18:07.479Z caller=node_exporter.go:115 level=info collector=vmstat
10月 11 07:18:07 ip-10-0-102-254.ap-northeast-1.compute.internalmydomain.local node_exporter[421117]: ts=2022-10-11T07:18:07.479Z caller=node_exporter.go:115 level=info collector=xfs
10月 11 07:18:07 ip-10-0-102-254.ap-northeast-1.compute.internalmydomain.local node_exporter[421117]: ts=2022-10-11T07:18:07.479Z caller=node_exporter.go:115 level=info collector=zfs
10月 11 07:18:07 ip-10-0-102-254.ap-northeast-1.compute.internalmydomain.local node_exporter[421117]: ts=2022-10-11T07:18:07.479Z caller=node_exporter.go:199 level=info msg="Listening on" address=:9100
10月 11 07:18:07 ip-10-0-102-254.ap-northeast-1.compute.internalmydomain.local node_exporter[421117]: ts=2022-10-11T07:18:07.479Z caller=tls_config.go:195 level=info msg="TLS is disabled." http2=false
Node Exporterの収集対象を制御する
Node Exporterの収集対象は、以下のオプションで制御できる。
「<name>」に指定する文字列はこちらの表で確認できる。
- デフォルトで無効な収集対象を有効にする:--collector.<name>
- デフォルトで有効な収集対象を無効にする:--no-collector.<name>
- 特定の収集対象のみ有効にする:--collector.disable-defaults --collector.<name>
実際に設定変更して確認してみる。
デフォルトで収集されているメトリクスの数を確認。
# curl -s http://localhost:9100/metrics | grep -v "#" | wc -l 568
デフォルトで有効な収集対象を全て無効にすると、メトリクス数は減っているが0にはならなかった。
無効化できない最低限のメトリクスがある模様。
# vim /etc/sysconfig/node_exporter OPTIONS="--collector.textfile.directory /var/lib/node_exporter/textfile_collector --collector.disable-defaults" # systemctl restart node_exporter # curl -s http://localhost:9100/metrics | grep -v "#" | wc -l 47 # curl -s http://localhost:9100/metrics | grep -v "#" | cut -f 1 -d " " > /tmp/disable-defaults.txt
cpuとmeminfoだけ有効化してみると、メトリクス数がやや増えた。
# vim /etc/sysconfig/node_exporter OPTIONS="--collector.textfile.directory /var/lib/node_exporter/textfile_collector --collector.disable-defaults --collector.cpu --collector.meminfo" # systemctl restart node_exporter # curl -s http://localhost:9100/metrics | grep -v "#" | wc -l 122
メトリクス項目の差分を見ると、CPU、メモリのメトリクスが増えていることが分かる。
# diff /tmp/disable-defaults.txt /tmp/cpu_meminfo.txt
(略)
> node_cpu_guest_seconds_total{cpu="0",mode="nice"}
> node_cpu_guest_seconds_total{cpu="0",mode="user"}
(略)
> node_memory_WritebackTmp_bytes
> node_memory_Writeback_bytes
> node_scrape_collector_duration_seconds{collector="cpu"}
> node_scrape_collector_duration_seconds{collector="meminfo"}
> node_scrape_collector_success{collector="cpu"}
> node_scrape_collector_success{collector="meminfo"}
cAdvisorでDockerコンテナのメトリクスを収集する
以下を参考に、cAdvisorを使って管理対象サーバのコンテナのメトリクスを収集してみる。
Monitoring Docker container metrics using cAdvisor | Prometheus
cAdvisorの起動
管理対象サーバでcAdvisorコンテナを起動する。
Advisorコンテナは、サーバ再起動後も自動起動してほしいので、上記リンクの起動コマンドに「--restart=always」を追加した。
# VERSION=v0.45.0 # docker run \ --volume=/:/rootfs:ro \ --volume=/var/run:/var/run:ro \ --volume=/sys:/sys:ro \ --volume=/var/lib/docker/:/var/lib/docker:ro \ --volume=/dev/disk/:/dev/disk:ro \ --publish=8080:8080 \ --detach=true \ --name=cadvisor \ --privileged \ --device=/dev/kmsg \ --restart=always \ gcr.io/cadvisor/cadvisor:$VERSION # docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES f36db3b97eee gcr.io/cadvisor/cadvisor:v0.45.0 "/usr/bin/cadvisor -…" 5 seconds ago Up 4 seconds (health: starting) 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp cadvisor
ブラウザで「http://{管理対象サーバのIP}:8080/」に接続すると、cAdvisorのWeb画面を参照できる。

また、cAdvisorが公開しているメトリクスを「http://localhost:8080/metrics」で確認できる。
# curl -s http://localhost:9100/metrics | head
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 3.1201e-05
go_gc_duration_seconds{quantile="0.25"} 6.0298e-05
go_gc_duration_seconds{quantile="0.5"} 8.5714e-05
go_gc_duration_seconds{quantile="0.75"} 0.000121806
go_gc_duration_seconds{quantile="1"} 0.003530947
go_gc_duration_seconds_sum 2.909751902
go_gc_duration_seconds_count 10781
# HELP go_goroutines Number of goroutines that currently exist.
各メトリクスの説明は以下を参照。
cadvisor/prometheus.md at master · google/cadvisor · GitHub
※ちなみに、以下のようにcAdvisorの実行オプションに--enable_metricsを追加することで、デフォルトで有効になっていない収集メトリクスを有効化できる(無効にしたい場合は--disable_metrics)。
--enable_metricsに指定する文字列は、上記メトリクス説明ページの表を参照。カンマ区切りで複数指定できる。
# VERSION=v0.45.0 # docker run \ --volume=/:/rootfs:ro \ --volume=/var/run:/var/run:ro \ --volume=/sys:/sys:ro \ --volume=/var/lib/docker/:/var/lib/docker:ro \ --volume=/dev/disk/:/dev/disk:ro \ --publish=8080:8080 \ --detach=true \ --name=cadvisor \ --privileged \ --device=/dev/kmsg \ --restart=always \ gcr.io/cadvisor/cadvisor:$VERSION \ --enable_metrics=cpu_topology,memory
確認用コンテナの起動
確認用に、Redisコンテナを起動する。
# docker run --publish=6379:6379 --detach=true --name=redis redis:latest # docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 8b5881b568b2 redis:latest "docker-entrypoint.s…" 2 seconds ago Up 1 second 0.0.0.0:6379->6379/tcp, :::6379->6379/tcp redis f36db3b97eee gcr.io/cadvisor/cadvisor:v0.45.0 "/usr/bin/cadvisor -…" 7 minutes ago Up 7 minutes (healthy) 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp cadvisor
cAdvisorはサーバ内に存在しているコンテナ単位にメトリクスを収集する。
ブラウザで「http://{管理対象サーバのIP}:8080/docker/redis」に接続すると、redisコンテナのメトリクスが見られる。

Prometheusの設定変更
cAdvisorからメトリクスを収集するよう、Prometheusに設定をする。
モニタリングサーバのprometheus.ymlに以下のように追記をする。
# vim /opt/docker/monitoring/prometheus/etc/prometheus.yml
global:
scrape_interval: 15s # Prometheusがtargetからメトリクスを取得する間隔
external_labels:
monitor: 'codelab-monitor'
scrape_configs:
# Prometheus
- job_name: 'prometheus'
scrape_interval: 5s # global.scrape_intervalを上書き
static_configs:
- targets: ['localhost:9090']
# Node Exporter
- job_name: node
file_sd_configs:
- refresh_interval: 30s # targetsファイルの読み込み間隔
files: # targetsファイルを記載
- /etc/prometheus/sd_files/node_targets.yml
# cAdvisor
- job_name: cadvisor
scrape_interval: 5s
file_sd_configs:
- refresh_interval: 30s # targetsファイルの読み込み間隔
files: # targetsファイルを記載
- /etc/prometheus/sd_files/cadvisor_targets.yml
# vim /opt/docker/monitoring/prometheus/etc/sd_files/cadvisor_targets.yml
- targets:
- {管理対象サーバのIP}:8080
labels:
service: cadvisor
Prometheusをリロードして、prometheus.ymlの変更を反映する。
# docker exec -it prometheus-2.37.1 killall -HUP prometheus
少し待ってからPrometheusのWeb画面で「Status」→「Targets」を確認すると、以下のようにcAdvisorが追加されている。

Grafanaのダッシュボードを作成
Node Exporter同様、インポートしてダッシュボードを作成する。 「Docker Container」というダッシュボードを使わせていただく。
インポートすると、以下のようにコンテナのメトリクスが表示される。

補足:cAdvisorの警告メッセージ
cAdvisorコンテナから、「There are no NVM devices!」というメッセージが出力され続けていることに気付いた。
# docker logs cadvisor I1005 07:08:45.103690 1 manager.go:1191] Exiting thread watching subcontainers I1005 07:08:45.103714 1 manager.go:405] Exiting global housekeeping thread I1005 07:08:45.104268 1 cadvisor.go:210] Exiting given signal: terminated W1005 07:10:20.790347 1 machine_libipmctl.go:64] There are no NVM devices! W1005 07:15:20.942362 1 machine_libipmctl.go:64] There are no NVM devices!
→Warningだし、特に問題無く動作しているように思える。できれば消したいが、消す方法が見つからなかった。
NVMデバイスがないサーバでは出力させ続けるしかないのかもしれない。
まとめ
- Docker ComposeでPrometheusとGrafanaを起動することで、簡単にモニタリング環境を構築できた。
- Node ExporterとcAdvisorを使用することで、ハードウェア・OS・コンテナのメトリクスを収集出来ることを確認した。
- 今後は以下も試してみたい。
- Promeheusuのリモートストレージの利用
- Node Exporterで独自メトリクスを収集 →やってみた。記事はこちら。
- Prometheusの他のServiceDiscovery方法を試す
- Prometheusのリラベル機能を試す
- ログ収集も統合出来ないか試す