kubeadmでKubernetes HAクラスタを構築する(CentOS7、k8s v1.17)
以前、勉強のためにKubernetes v1.17でHAクラスタ(高可用性クラスタ)を構築した際のメモ。
現時点(2022年10月)のK8s最新バージョンはv1.25なので、やや古くなってしまっているが、大まかな手順は変わって無さそうなので記録として残しておく。
気が向いたらK8sやOSバージョンを新しいものにして再度構築してみたいと思っている。
構成の検討
構築するHAクラスタの構成を決める。
HAクラスタの構成にはオプションがあるので、まずは以下ページを見てみる。
高可用性トポロジーのためのオプション | Kubernetes
→etcdクラスターを、K8sのコントロールプレーンと同居させるかどうかで、2つのパターンがある。
今回は検証目的で、etcd専用のマシンを用意するのも大変なので、「積層コントロールプレーンノードを使用する方法」を選択した。HAクラスタの構築手順は、以下ページに載っている。
kubeadmを使用した高可用性クラスターの作成 | Kubernetes
→HAクラスタの場合は、kube-apiserver用ロードバランサーが必要とのこと。今回はNginxを使うことにした。
→通常のK8sクラスタと同様、SCNIが必要なので、何を使うか決めておく。
CNIは代表的なものとしてCalico、Flannelがあるが、FlannelはK8sの「Network Policy」機能が使えないので、Calicoを採用した。
※以下の理由からもCalicoをオススメする。
kubeadmを使用したクラスターの作成 | Kubernetes
→2022年10月時点で、以下の記載がある。
特別な理由がなければ、kubeadmでK8sインストールする場合はCalicoを選択するのがよさそう。
現在、Calicoはkubeadmプロジェクトがe2eテストを実施している唯一のCNIプラグインです。
構成図
前項での検討を踏まえて、構築する環境の構成イメージは以下の通り。

環境
- OS:CentOS7
- スペック:2vcpu、メモリ4GB、ディスクサイズは適当に30~50GBくらい。
- ネットワーク:yumやdocker pullを実行するため、各ノードからインターネットに接続可能にしておく。
- ホスト名、IPアドレスは以下の通り。
・LBノード#1:dev-klb-001(192.168.10.190)
・Masterノード#1:dev-k8s-001(192.168.10.191)
・Masterノード#2:dev-k8s-002(192.168.10.192)
・Masterノード#3:dev-k8s-003(192.168.10.193)
・Workerノード#1:dev-k8s-101(192.168.10.194)
・Workerノード#2:dev-k8s-102(192.168.10.195)
・Workerノード#3:dev-k8s-103(192.168.10.196)
→上記の7台の仮想マシンを、ローカルの環境に構築した。
※AWSnのEC2など、パブリッククラウドのIaaSで構築した方が手軽で良いかと思ったが、ServiceのLoadbalancerTypeが使用できないなどの制約(※以下ページ参照)があるため、ローカル環境に構築した。
kubeadmを使用した高可用性クラスターの作成 | Kubernetes
このページはクラウド上でクラスターを構築することには対応していません。ここで説明されているどちらのアプローチも、クラウド上で、LoadBalancerタイプのServiceオブジェクトや、動的なPersistentVolumeを利用して動かすことはできません。
構築作業
kubeadmのインストール
以下を参考に、kubeadmをインストールする。
kubeadmのインストール | Kubernetes
Masterノード、Workerノード全台で以下を実施する。
kubeadmのインストール要件を満たすように、OS設定の確認、変更を行う。
MACアドレスを表示し、他ノードと重複していないか確認する # ip link show eth0 | grep link | cut -d " " -f 6 UUIDを表示し、他ノードと重複していないか確認する # cat /sys/class/dmi/id/product_uuid swapの無効化 # swapon -s Filename Type Size Used Priority /dev/dm-1 partition 2097148 0 -2 # swapoff -a # swapon -s swapの行をコメントアウトする # vim /etc/fstab SELinuxの無効化 # sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config # reboot Firewalldの無効化 # systemctl stop firewalld # systemctl disable firewalld K8sはIPフォワード機能を使うので、有効にする # echo "net.ipv4.ip_forward = 1" >> /etc/sysctl.conf # sysctl -p net.ipv4.ip_forward = 1
Dockerをインストールする。
必要なパッケージのインストール # yum install -y yum-utils device-mapper-persistent-data lvm2 dockerをインストール # yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo # yum update -y && yum install -y --setopt=obsoletes=0 docker-ce-19.03.8 # rpm -qa | grep docker | sort docker-ce-19.03.8-3.el7.x86_64 docker-ce-cli-19.03.8-3.el7.x86_64 dockerを起動&自動起動設定 # systemctl enable docker && systemctl start docker # docker version Client: Docker Engine - Community Version: 19.03.8 API version: 1.40 Go version: go1.12.17 Git commit: afacb8b Built: Wed Mar 11 01:27:04 2020 OS/Arch: linux/amd64 Experimental: false Server: Docker Engine - Community Engine: Version: 19.03.8 API version: 1.40 (minimum version 1.12) Go version: go1.12.17 Git commit: afacb8b Built: Wed Mar 11 01:25:42 2020 OS/Arch: linux/amd64 Experimental: false containerd: Version: 1.2.13 GitCommit: 7ad184331fa3e55e52b890ea95e65ba581ae3429 runc: Version: 1.0.0-rc10 GitCommit: dc9208a3303feef5b3839f4323d9beb36df0a9dd docker-init: Version: 0.18.0 GitCommit: fec3683 dockerのcgrop driverがkubeletのデフォルト設定である「cgroupfs」であることを確認 # docker info | grep -i cgroup WARNING: bridge-nf-call-iptables is disabled WARNING: bridge-nf-call-ip6tables is disabled Cgroup Driver: cgroupfs
kubeadmをインストールする
yumレポジトリの追加
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF
kubeadm・kubelet・kubectlインストール
# yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
kubelet起動&自動起動設定
# systemctl enable --now kubelet
kubeletは正常に起動していない(activatingのまま)が、この時点ではこれが正常。
# systemctl status kubelet
● kubelet.service - kubelet: The Kubernetes Node Agent
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Drop-In: /usr/lib/systemd/system/kubelet.service.d
mq10-kubeadm.conf
Active: activating (auto-restart) (Result: exit-code) since 月 2020-03-16 19:49:13 JST; 7s ago
Docs: https://kubernetes.io/docs/
Process: 9882 ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS $KUBELET_CONFIG_ARGS $KUBELET_KUBEADM_ARGS $KUBELET_EXTRA_ARGS (code=exited, status=255)
Main PID: 9882 (code=exited, status=255)
3月 16 19:49:13 dev-k8s-001 systemd[1]: kubelet.service: main process exited, code=exited, status=255/n/a
3月 16 19:49:13 dev-k8s-001 systemd[1]: Unit kubelet.service entered failed state.
3月 16 19:49:13 dev-k8s-001 systemd[1]: kubelet.service failed.
net.bridge.bridge-nf-call-iptablesの設定を実施
# cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
# sysctl --system
# sysctl -n net.bridge.bridge-nf-call-iptables
1
br_netfilterモジュールが稼働していることを確認
# lsmod | grep br_netfilter
br_netfilter 22256 0
bridge 151336 1 br_netfilter
ノード間がホスト名で通信できるよう、各ノードのhostsファイルに全ノードのホスト名とIPアドレスを記載しておく。 (DNSサーバがある環境ならそれで名前解決すればOK。)
# vim /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.10.190 dev-klb-001 192.168.10.191 dev-k8s-001 192.168.10.192 dev-k8s-002 192.168.10.193 dev-k8s-003 192.168.10.194 dev-k8s-101 192.168.10.195 dev-k8s-102 192.168.10.196 dev-k8s-103
ロードバランサー(LBノード)の構築
ロードバランサーとしてNginxを使う。
6443ポートで受け付けたトラフィックを、Masterノード3台の6443ポートに転送する設定にする。
LBノードで以下のようにnginxを設定して起動しておく
# cat /etc/nginx/nginx.conf
user nginx;
worker_processes 1;
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024;
}
stream {
upstream kube_apiserver {
least_conn;
server 192.168.10.191:6443;
server 192.168.10.192:6443;
server 192.168.10.193:6443;
}
server {
listen 6443;
proxy_pass kube_apiserver;
proxy_timeout 10m;
proxy_connect_timeout 1s;
}
}
http {
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
# include /etc/nginx/conf.d/*.conf;
}
Masterノードの構築
Masterノード#1で以下を実行する。
kubeadmの設定ファイルを書く。
certSANsやcontrolPlaneEndpointをMASTERノードでは無くLBノードにするのがポイント。
# vim /etc/kubernetes/kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta1
kind: ClusterConfiguration
kubernetesVersion: v1.17.4
apiServer:
certSANs:
- dev-klb-001
networking:
podSubnet: 10.64.0.0/16
controlPlaneEndpoint: dev-klb-001:6443
initを実行する。出力結果は後々使用するため控えておく。
# kubeadm init --config=/etc/kubernetes/kubeadm-config.yaml
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join dev-klb-001:6443 --token uqvtkv.clz9iyjobripct2w \
--discovery-token-ca-cert-hash sha256:2d4d8d85ad6eeb3e08d349147b12202eb09dfe06797d31d44360b12c4b6377e0 \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join dev-klb-001:6443 --token uqvtkv.clz9iyjobripct2w \
--discovery-token-ca-cert-hash sha256:2d4d8d85ad6eeb3e08d349147b12202eb09dfe06797d31d44360b12c4b6377e0
init実行時に表示されたコマンドを実行する
# mkdir -p $HOME/.kube
# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
# sudo chown $(id -u):$(id -g) $HOME/.kube/config
kubectlが使えるようになる。この時点ではSTATUSはNotReadyで大丈夫。
# kubectl get node
NAME STATUS ROLES AGE VERSION
dev-k8s-001 NotReady master 7m50s v1.17.4
CNIとしてCalicoをデプロイする。まずyamlの以下2点を修正する。
・CALICO_IPV4POOL_IPIPをoffにする
・CALICO_IPV4POOL_CIDRのvalueはkubeadm-config.yamlのpodSubnetと一致させる。
# wget https://docs.projectcalico.org/manifests/calico.yaml
# vim calico.yaml
(略)
# Enable IPIP
- name: CALICO_IPV4POOL_IPIP
value: "off"
# Set MTU for tunnel device used if ipip is enabled
- name: FELIX_IPINIPMTU
valueFrom:
configMapKeyRef:
name: calico-config
key: veth_mtu
# The default IPv4 pool to create on startup if none exists. Pod IPs will be
# chosen from this range. Changing this value after installation will have
# no effect. This should fall within `--cluster-cidr`.
- name: CALICO_IPV4POOL_CIDR
value: "10.64.0.0/16"
(略)
Calicoを展開する。
# kubectl apply -f calico.yaml
Calicoのバージョンを確認
# grep image calico.yaml
image: calico/cni:v3.13.2
image: calico/cni:v3.13.2
image: calico/pod2daemon-flexvol:v3.13.2
image: calico/node:v3.13.2
image: calico/kube-controllers:v3.13.2
PodのStatusが全てRunnnigになったらOK。
# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-5554fcdcf9-zmdlw 1/1 Running 0 45s
calico-node-6c4zt 1/1 Running 0 45s
coredns-6955765f44-frnbn 1/1 Running 0 11m
coredns-6955765f44-r28fc 1/1 Running 0 11m
etcd-dev-k8s-001 1/1 Running 0 11m
kube-apiserver-dev-k8s-001 1/1 Running 0 11m
kube-controller-manager-dev-k8s-001 1/1 Running 0 11m
kube-proxy-z5r6m 1/1 Running 0 11m
kube-scheduler-dev-k8s-001 1/1 Running 0 11m
K8sの証明書ファイルは全Masterノードで同じものを使うため、Masterノード#2、#3にコピーする。
# USER=root
# CONTROL_PLANE_IPS="dev-k8s-002 dev-k8s-003"
# for host in ${CONTROL_PLANE_IPS}; do
scp /etc/kubernetes/pki/ca.crt "${USER}"@$host:
scp /etc/kubernetes/pki/ca.key "${USER}"@$host:
scp /etc/kubernetes/pki/sa.key "${USER}"@$host:
scp /etc/kubernetes/pki/sa.pub "${USER}"@$host:
scp /etc/kubernetes/pki/front-proxy-ca.crt "${USER}"@$host:
scp /etc/kubernetes/pki/front-proxy-ca.key "${USER}"@$host:
scp /etc/kubernetes/pki/etcd/ca.crt "${USER}"@$host:etcd-ca.crt
scp /etc/kubernetes/pki/etcd/ca.key "${USER}"@$host:etcd-ca.key
scp /etc/kubernetes/admin.conf "${USER}"@$host:
done
Masterノード#2、#3で以下を実行する
Masterノード#1から転送した証明書をK8sのディレクトリに配置する。
# mkdir -p /etc/kubernetes/pki/etcd
# mv /root/ca.crt /etc/kubernetes/pki/
# mv /root/ca.key /etc/kubernetes/pki/
# mv /root/sa.pub /etc/kubernetes/pki/
# mv /root/sa.key /etc/kubernetes/pki/
# mv /root/front-proxy-ca.crt /etc/kubernetes/pki/
# mv /root/front-proxy-ca.key /etc/kubernetes/pki/
# mv /root/etcd-ca.crt /etc/kubernetes/pki/etcd/ca.crt
# mv /root/etcd-ca.key /etc/kubernetes/pki/etcd/ca.key
# mv /root/admin.conf /etc/kubernetes/admin.conf
Masterノードとしてクラスタに参加する。
Masterノード#1でkubeadm initを実行したときに表示されたコマンドを実行する。
# kubeadm join dev-klb-001:6443 --token uqvtkv.clz9iyjobripct2w \
--discovery-token-ca-cert-hash sha256:2d4d8d85ad6eeb3e08d349147b12202eb09dfe06797d31d44360b12c4b6377e0 \
--control-plane
Masterノードの状態を確認する
STATUSが3台ともReadyになっていればOK。 # kubectl get node NAME STATUS ROLES AGE VERSION dev-k8s-001 Ready master 70m v1.17.4 dev-k8s-002 Ready master 17m v1.17.4 dev-k8s-003 Ready master 39m v1.17.4 PodのStatusが全てRunnnigになったらOK。 # kubectl get pod -n kube-system NAME READY STATUS RESTARTS AGE calico-kube-controllers-5554fcdcf9-zmdlw 1/1 Running 0 18m calico-node-5hwlw 1/1 Running 0 6m14s calico-node-6c4zt 1/1 Running 0 18m calico-node-f4d48 1/1 Running 0 14m coredns-6955765f44-frnbn 1/1 Running 0 28m coredns-6955765f44-r28fc 1/1 Running 0 28m etcd-dev-k8s-001 1/1 Running 0 28m etcd-dev-k8s-002 1/1 Running 0 14m etcd-dev-k8s-003 1/1 Running 0 6m12s kube-apiserver-dev-k8s-001 1/1 Running 0 28m kube-apiserver-dev-k8s-002 1/1 Running 0 14m kube-apiserver-dev-k8s-003 1/1 Running 0 6m14s kube-controller-manager-dev-k8s-001 1/1 Running 1 28m kube-controller-manager-dev-k8s-002 1/1 Running 0 14m kube-controller-manager-dev-k8s-003 1/1 Running 0 6m14s kube-proxy-k26ls 1/1 Running 0 6m14s kube-proxy-rql7k 1/1 Running 0 14m kube-proxy-z5r6m 1/1 Running 0 28m kube-scheduler-dev-k8s-001 1/1 Running 1 28m kube-scheduler-dev-k8s-002 1/1 Running 0 14m kube-scheduler-dev-k8s-003 1/1 Running 0 6m14s
kubectlのtabでのコマンド補完とエイリアスを設定しておく(全てのMasterノードでやっておく)。
コマンド補完とエイリアスの設定 # source <(kubectl completion bash) # echo "source <(kubectl completion bash)" >> ~/.bashrc # echo "alias k=kubectl" >> ~/.bashrc # echo "complete -F __start_kubectl k" >> ~/.bashrc 「k」でkubectlを実行できる。tab補完も効く。 # k get node NAME STATUS ROLES AGE VERSION dev-k8s-001 Ready master 70m v1.17.4 dev-k8s-002 Ready master 17m v1.17.4 dev-k8s-003 Ready master 39m v1.17.4
※ちなみに、kube-proxyをipvsモードで動作させたい場合は、kubeadm-config.yamlを以下のようにすればよい。
# cat /etc/kubernetes/kubeadm-config.yaml apiVersion: kubeadm.k8s.io/v1beta1 kind: ClusterConfiguration kubernetesVersion: v1.17.4 apiServer: certSANs: - dev-klb-001 networking: podSubnet: 10.64.0.0/16 controlPlaneEndpoint: dev-klb-001:6443 --- apiVersion: kubeproxy.config.k8s.io/v1alpha1 kind: KubeProxyConfiguration mode: ipvs
Workerノードの構築
全Workerノードで以下を実行する。
Workerノードとしてクラスタに参加する。
Masterノード#1でkubeadm initを実行したときに表示されたコマンドを実行する。
# kubeadm join dev-klb-001:6443 --token uqvtkv.clz9iyjobripct2w \
--discovery-token-ca-cert-hash sha256:2d4d8d85ad6eeb3e08d349147b12202eb09dfe06797d31d44360b12c4b6377e0
(略)
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
Masterノードで全ノードのSTATUSがReadyであることを確認する。
# k get node NAME STATUS ROLES AGE VERSION dev-k8s-001 Ready master 37m v1.17.4 dev-k8s-002 Ready master 23m v1.17.4 dev-k8s-003 Ready master 15m v1.17.4 dev-k8s-101 Ready <none> 6m16s v1.17.4 dev-k8s-102 Ready <none> 3m6s v1.17.4 dev-k8s-103 Ready <none> 2m32s v1.17.4
動作確認
構築できたので、まずはK8sクラスタとして正常に動作しているか確認する。
機能を色々試す
HAクラスタだとkube-apiserverへの接続がLBノード経由になっていることが気になったので、適当にPodを起動して、kube-apiserverに接続できるか確認してみる。
適当にPodを起動 # kubectl run testpod --image=centos:7 -i --tty --rm PodからServiceの名前解決が出来ていることを確認する [root@testpod-7f47d69745-k6jmh /]# nslookup kubernetes.default.svc.cluster.local Server: 10.96.0.10 Address: 10.96.0.10#53 Name: kubernetes.default.svc.cluster.local Address: 10.96.0.1 Podからkube-apiserverへの接続ができているか確認する。 [root@testpod-7f47d69745-k6jmh /]# curl https://10.96.0.1:443/api?timeout=32s curl: (60) Peer certificate cannot be authenticated with known CA certificates More details here: http://curl.haxx.se/docs/sslcerts.html curl performs SSL certificate verification by default, using a "bundle" of Certificate Authority (CA) public keys (CA certs). If the default bundle file isn't adequate, you can specify an alternate file using the --cacert option. If this HTTPS server uses a certificate signed by a CA represented in the bundle, the certificate verification probably failed due to a problem with the certificate (it might be expired, or the name might not match the domain name in the URL). If you'd like to turn off curl's verification of the certificate, use the -k (or --insecure) option. →証明書を指定せずにアクセスしたので警告メッセージが出ているが、接続自体は成功している。
Pod間通信ができていることを確認する。
テスト用Deploymentを作成する。
# vim sample-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-deployment
spec:
replicas: 3
selector:
matchLabels:
app: sample-app
template:
metadata:
labels:
app: sample-app
spec:
containers:
- name: nginx-container
image: nginx:1.12
ports:
- containerPort: 80
# kubectl apply -f sample-deployment.yaml
deployment.apps/sample-deployment created
問題なく起動している。
# k get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
sample-deployment 3/3 3 3 3m41s
# k get pod
NAME READY STATUS RESTARTS AGE
sample-deployment-c6c6778b4-6l98t 1/1 Running 0 3m53s
sample-deployment-c6c6778b4-98vtp 1/1 Running 0 3m53s
sample-deployment-c6c6778b4-xlnzv 1/1 Running 0 3m53s
Pod内のindex.htmlの中身をホスト名に変更し、どのPodにアクセスしたか判別できるようにする。
# for PODNAME in `kubectl get pod -l app=sample-app -o jsonpath='{.items[*].metadata.name}'`; do kubectl exec -it ${PODNAME} -- cp /etc/hostname /usr/share/nginx/html/index.html; done
# for PODNAME in `kubectl get pod -l app=sample-app -o jsonpath='{.items[*].metadata.name}'`; do kubectl exec -it ${PODNAME} -- cat /usr/share/nginx/html/index.html; done
sample-deployment-c6c6778b4-6l98t
sample-deployment-c6c6778b4-98vtp
sample-deployment-c6c6778b4-xlnzv
ノードを跨いだPod間通信が出来ているか確認する。
Podは3台のWorkerノードそれぞれで起動している。
# k get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
sample-deployment-c6c6778b4-6l98t 1/1 Running 0 4m50s 10.64.85.64 dev-k8s-101 <none> <none>
sample-deployment-c6c6778b4-98vtp 1/1 Running 0 4m50s 10.64.184.65 dev-k8s-102 <none> <none>
sample-deployment-c6c6778b4-xlnzv 1/1 Running 0 4m50s 10.64.15.192 dev-k8s-103 <none> <none>
テスト用Podを起動して、各Podにアクセスできることを確認。
# kubectl run testpod --image=centos:7 -i --tty --rm
[root@testpod-6fcc4dc99-5tq4f /]# curl http://10.64.85.64
sample-deployment-c6c6778b4-6l98t
[root@testpod-6fcc4dc99-5tq4f /]# curl http://10.64.184.65
sample-deployment-c6c6778b4-98vtp
[root@testpod-6fcc4dc99-5tq4f /]# curl http://10.64.15.192
sample-deployment-c6c6778b4-xlnzv
ClusterIPタイプのServiceを試してみる。
ClusterIPタイプのServiceを作成。
# cat sample-clusterip.yaml
apiVersion: v1
kind: Service
metadata:
name: sample-clusterip
spec:
type: ClusterIP
ports:
- name: "http-port"
protocol: "TCP"
port: 8080
targetPort: 80
selector:
app: sample-app
# k apply -f sample-clusterip.yaml
# kubectl describe service sample-clusterip
Name: sample-clusterip
Namespace: default
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Service","metadata":{"annotations":{},"name":"sample-clusterip","namespace":"default"},"spec":{"ports":[{"name"...
Selector: app=sample-app
Type: ClusterIP
IP: 10.109.85.22
Port: http-port 8080/TCP
TargetPort: 80/TCP
Endpoints: 10.64.15.192:80,10.64.184.65:80,10.64.85.64:80
Session Affinity: None
Events: <none>
テスト用PodからClusterIPのエンドポイント(sample-clusterip:8080)に対してアクセスすると、配下の各Podに振り分けられていることが確認できる。
# kubectl run testpod --image=centos:7 -i --tty --rm
kubectl run --generator=deployment/apps.v1 is DEPRECATED and will be removed in a future version. Use kubectl run --generator=run-pod/v1 or kubectl create instead.
If you don't see a command prompt, try pressing enter.
[root@testpod-6fcc4dc99-qk8qb /]# curl -s http://sample-clusterip:8080/
sample-deployment-c6c6778b4-xlnzv
[root@testpod-6fcc4dc99-qk8qb /]# curl -s http://sample-clusterip:8080/
sample-deployment-c6c6778b4-98vtp
[root@testpod-6fcc4dc99-qk8qb /]# curl -s http://sample-clusterip:8080/
sample-deployment-c6c6778b4-6l98t
clusterIPを削除する。
# k delete -f sample-clusterip.yaml
NodePortタイプのServiceを試してみる。
NodePortタイプのServiceを作成する。
# cat sample-nodeport.yaml
apiVersion: v1
kind: Service
metadata:
name: sample-nodeport
spec:
type: NodePort
ports:
- name: "http-port"
protocol: "TCP"
port: 8080
targetPort: 80
nodePort: 30080
selector:
app: sample-app
# kubectl apply -f sample-nodeport.yaml
# kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 57m <none>
sample-nodeport NodePort 10.109.230.138 <none> 8080:30080/TCP 5s app=sample-app
# kubectl describe service sample-nodeport
Name: sample-nodeport
Namespace: default
Labels: <none>
Annotations: kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"v1","kind":"Service","metadata":{"annotations":{},"name":"sample-nodeport","namespace":"default"},"spec":{"ports":[{"name":...
Selector: app=sample-app
Type: NodePort
IP: 10.109.230.138
Port: http-port 8080/TCP
TargetPort: 80/TCP
NodePort: http-port 30080/TCP
Endpoints: 10.64.15.192:80,10.64.184.65:80,10.64.85.64:80
Session Affinity: None
External Traffic Policy: Cluster
Events: <none>
どのノードに対してアクセスしても、各Podに振り分けされる。
[root@dev-k8s-001 work]# curl http://dev-k8s-101:30080/
sample-deployment-c6c6778b4-6l98t
[root@dev-k8s-001 work]# curl http://dev-k8s-102:30080/
sample-deployment-c6c6778b4-98vtp
[root@dev-k8s-001 work]# curl http://dev-k8s-103:30080/
sample-deployment-c6c6778b4-98vtp
[root@dev-k8s-001 work]# curl http://dev-k8s-101:30080/
sample-deployment-c6c6778b4-98vtp
[root@dev-k8s-001 work]# curl http://dev-k8s-101:30080/
sample-deployment-c6c6778b4-6l98t
[root@dev-k8s-001 work]# curl http://dev-k8s-101:30080/
sample-deployment-c6c6778b4-xlnzv
NodePortを削除する。
# k delete -f sample-nodeport.yaml
テスト用Deploymentを削除する。
# kubectl delete -f sample-deployment.yaml deployment.apps "sample-deployment" deleted # k get deployment No resources found in default namespace.
テストツール(sonobuoy)で評価する
KubernetesクラスタのE2Eテストを実行してくれるsonobuoyというツールがある。
これを実行して、クラスタの正常性を確認してみる。
sonobuoy.io
sonobuoyをダウンロードする
# wget https://github.com/vmware-tanzu/sonobuoy/releases/download/v0.18.0/sonobuoy_0.18.0_linux_amd64.tar.gz
# tar -xvf sonobuoy_0.18.0_linux_amd64.tar.gz
sonobuoyを開始する
# ./sonobuoy run
sonobupyのPodがクラスタ上に展開されたことが確認できる。
# k -n sonobuoy get pod
NAME READY STATUS RESTARTS AGE
sonobuoy 1/1 Running 0 3m58s
sonobuoy-e2e-job-3d8ef3ce1e3e4f34 2/2 Running 0 3m46s
sonobuoy-systemd-logs-daemon-set-079b4675f756435f-2hv6p 2/2 Running 0 3m46s
sonobuoy-systemd-logs-daemon-set-079b4675f756435f-54m58 2/2 Running 0 3m45s
sonobuoy-systemd-logs-daemon-set-079b4675f756435f-fswt7 2/2 Running 0 3m45s
sonobuoy-systemd-logs-daemon-set-079b4675f756435f-k2g46 2/2 Running 0 3m46s
sonobuoy-systemd-logs-daemon-set-079b4675f756435f-pdc87 2/2 Running 0 3m46s
sonobuoy-systemd-logs-daemon-set-079b4675f756435f-xf6qq 2/2 Running 0 3m45s
statusコマンドで実行にかかる時間が表示できる。60分くらいかかる模様。
# ./sonobuoy status
PLUGIN STATUS RESULT COUNT
e2e running 1
systemd-logs complete 6
Sonobuoy is still running. Runs can take up to 60 minutes.
しばらく経ってstatusを実行すると完了している。
RESULTがpassedとなっているので問題なさそう。
# ./sonobuoy status
PLUGIN STATUS RESULT COUNT
e2e complete passed 1
systemd-logs complete passed 6
Sonobuoy has completed. Use `sonobuoy retrieve` to get results.
結果のサマリは以下のように取得できる。
# results=$(./sonobuoy retrieve)
# ./sonobuoy results $results
Plugin: e2e
Status: passed
Total: 4842
Passed: 278
Failed: 0
Skipped: 4564
Plugin: systemd-logs
Status: passed
Total: 6
Passed: 6
Failed: 0
Skipped: 0
結果の詳細レポートは以下のように取得できる。
# mkdir result
# tar zxf 202004090501_sonobuoy_81410fb8-12ef-4f6c-9150-3eb10d036ca9.tar.gz -C result/
# ll result/
合計 12
drwxr-xr-x 8 root root 120 4月 9 15:45 hosts
drwxr-xr-x 2 root root 80 4月 9 15:46 meta
drwxr-xr-x 4 root root 37 4月 9 15:45 plugins
drwxr-xr-x 3 root root 22 4月 9 15:45 podlogs
drwxr-xr-x 4 root root 31 4月 9 15:45 resources
-rw-r--r-- 1 root root 4501 4月 9 15:45 servergroups.json
-rw-r--r-- 1 root root 226 4月 9 15:45 serverversion.json
sonobouy関連リソースを削除する。
# ./sonobuoy delete --wait
sonobuoyにはE2Eテスト実行後に「Leaked End-to-end namespaces」という問題が発生する可能性があるため、念のため以下も実行する。
# ./sonobuoy delete --all
可用性の確認
Kubernetesクラスタとしては正常に動作していることが確認できた。
HAクラスタなので、Masterノードが1台ダウンしても動作することも確認したい。
Masterノード1台ダウン
事前準備として、前項で使ったDeployment、Service(NodePort)をクラスタに展開する。
Deployment、Pod、NodePortを以下のように作成した。 # kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES sample-deployment-c6c6778b4-dhvhd 1/1 Running 0 16s 10.64.85.99 dev-k8s-101 <none> <none> sample-deployment-c6c6778b4-j5blq 1/1 Running 0 16s 10.64.184.89 dev-k8s-102 <none> <none> sample-deployment-c6c6778b4-mwp6p 1/1 Running 0 16s 10.64.15.205 dev-k8s-103 <none> <none> # kubectl get deployment -o wide NAME READY UP-TO-DATE AVAILABLE AGE CONTAINERS IMAGES SELECTOR sample-deployment 3/3 3 3 24s nginx-container nginx:1.12 app=sample-app # kubectl get svc -o wide NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 5h44m <none> sample-nodeport NodePort 10.109.40.18 <none> 8080:30080/TCP 21s app=sample-app
クラスタ外のサーバからNodePortに接続し続けておく。 (接続先はWorkerノードにする。)
#watch -n 2 "timeout 1 curl 192.168.10.194:30080"
この状態でMaster#1をシャットダウンし、NodePortへの接続に影響がないか、クラスタへのリソースのデプロイができるか確認してみる。
Masterノード#1(dev-k8s-001)をシャットダウンさせてみる。シャットダウンから1分以内に、dev-k8s-001がNotReadyになった。 また、NodePortへの接続には影響は無かった。
# k get node NAME STATUS ROLES AGE VERSION dev-k8s-001 NotReady master 6h18m v1.17.4 dev-k8s-002 Ready master 6h3m v1.17.4 dev-k8s-003 Ready master 5h55m v1.17.4 dev-k8s-101 Ready <none> 5h46m v1.17.4 dev-k8s-102 Ready <none> 5h43m v1.17.4 dev-k8s-103 Ready <none> 5h42m v1.17.4
kube-system namespaceにあるPodを確認すると、Masterノード#1で動作していたcorednsとcalico-controllerは別のノードに移動していることが分かる。
kube-apiserverとetcdはダウンを検知できておらず、STATUSがRunningのまま。
これが正しい挙動なのかは情報が無く分からなかった。
# k get pod -n kube-system -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES calico-kube-controllers-5554fcdcf9-8zrj4 1/1 Running 0 104s 10.64.85.105 dev-k8s-101 <none> <none> calico-kube-controllers-5554fcdcf9-zmdlw 1/1 Terminating 0 6h13m 10.64.68.2 dev-k8s-001 <none> <none> calico-node-5hwlw 1/1 Running 0 6h1m 192.168.10.193 dev-k8s-003 <none> <none> calico-node-6c4zt 1/1 Running 0 6h13m 192.168.10.191 dev-k8s-001 <none> <none> calico-node-f4d48 1/1 Running 0 6h9m 192.168.10.192 dev-k8s-002 <none> <none> calico-node-r4krr 1/1 Running 0 5h52m 192.168.10.194 dev-k8s-101 <none> <none> calico-node-vncqb 1/1 Running 1 5h49m 192.168.10.195 dev-k8s-102 <none> <none> calico-node-zzdwp 1/1 Running 0 5h49m 192.168.10.196 dev-k8s-103 <none> <none> coredns-6955765f44-frnbn 1/1 Terminating 0 6h24m 10.64.68.1 dev-k8s-001 <none> <none> coredns-6955765f44-gzflk 1/1 Running 0 104s 10.64.15.210 dev-k8s-103 <none> <none> coredns-6955765f44-psw2r 1/1 Running 0 104s 10.64.184.96 dev-k8s-102 <none> <none> coredns-6955765f44-r28fc 1/1 Terminating 0 6h24m 10.64.68.0 dev-k8s-001 <none> <none> etcd-dev-k8s-001 1/1 Running 0 6h24m 192.168.10.191 dev-k8s-001 <none> <none> etcd-dev-k8s-002 1/1 Running 0 6h9m 192.168.10.192 dev-k8s-002 <none> <none> etcd-dev-k8s-003 1/1 Running 0 6h1m 192.168.10.193 dev-k8s-003 <none> <none> kube-apiserver-dev-k8s-001 1/1 Running 0 6h24m 192.168.10.191 dev-k8s-001 <none> <none> kube-apiserver-dev-k8s-002 1/1 Running 0 6h9m 192.168.10.192 dev-k8s-002 <none> <none> kube-apiserver-dev-k8s-003 1/1 Running 0 6h1m 192.168.10.193 dev-k8s-003 <none> <none> kube-controller-manager-dev-k8s-001 1/1 Running 1 6h24m 192.168.10.191 dev-k8s-001 <none> <none> kube-controller-manager-dev-k8s-002 1/1 Running 0 6h9m 192.168.10.192 dev-k8s-002 <none> <none> kube-controller-manager-dev-k8s-003 1/1 Running 0 6h1m 192.168.10.193 dev-k8s-003 <none> <none> kube-proxy-bt8zk 1/1 Running 1 5h49m 192.168.10.195 dev-k8s-102 <none> <none> kube-proxy-dhxzg 1/1 Running 0 5h52m 192.168.10.194 dev-k8s-101 <none> <none> kube-proxy-k26ls 1/1 Running 0 6h1m 192.168.10.193 dev-k8s-003 <none> <none> kube-proxy-q5k4l 1/1 Running 0 5h49m 192.168.10.196 dev-k8s-103 <none> <none> kube-proxy-rql7k 1/1 Running 0 6h9m 192.168.10.192 dev-k8s-002 <none> <none> kube-proxy-z5r6m 1/1 Running 0 6h24m 192.168.10.191 dev-k8s-001 <none> <none> kube-scheduler-dev-k8s-001 1/1 Running 1 6h24m 192.168.10.191 dev-k8s-001 <none> <none> kube-scheduler-dev-k8s-002 1/1 Running 0 6h9m 192.168.10.192 dev-k8s-002 <none> <none> kube-scheduler-dev-k8s-003 1/1 Running 0 6h1m 192.168.10.193 dev-k8s-003 <none> <none>
この状態でDeploymentやServiceを作成して接続確認してみたが、特に問題なく実行できた。
(kube-apiserverとetcdは他のMasterノードでも動作しているので、Masterノード#1から移動していないくも、問題ないのかもしれない。)
また、Masterノード#1を起動すると自動的にSTATUSがReadyとなった。
ただし、別ノード移動したPod(corednsとcalico-controller)は自動的にMasterノード#1に戻って来ることは無いため、再配置したい場合はrollout等を実行する必要がある。
Masterノードが1台ダウンしても、Kubernetesクラスタとしては継続して使用できることが確認できた。
※corednsとcalico-controllerはMasterノード上で稼働すべきだと思うが、上記ではMasterノードダウン時にWorkerノードへ移動してしまっている。
affinityやtolerationを使用して、Masterノード上にしか移動されないような制御が必要だと思う。
※上記では、ノードダウンからPod移動までに約5分かかった。
これは、v1.13.0からTaintBasedEvictionというPod退避機能がデフォルトで有効になったため。
tolerationSecondsがデフォルトでは300秒なので、Pod移動開始までに5分かかる。
tolerationSecondsを短くすれば、移動開始までの待ち時間を短縮することができるらしい。
https://kubernetes.io/docs/concepts/configuration/taint-and-toleration/#taint-based-evictions
Masterノード2台ダウン
HAクラスタはRaftアルゴリズムで実現しているため、3台クラスタの場合はMasterは1台ダウンまでは許容できる。 2台ダウンした場合どうなるか試したところ、以下の挙動となった。
- Masterノードが2台ダウンしても、起動済みのPodの稼働とNodePortへの接続には影響は無かった。
- ただし、Podの移動や状態の取得、Pod障害時の自動復旧など、コントロールプレーンへのアクセスが必要なアクションは全て動作しなかった。
テストツール(sonobuoy)で評価する(※上手くいかない)
上記だけでHAクラスタとして正常に動作していると言って良いのか不安だったため、Sonobuoyを使うことを考えた。
Masterノードが1台ダウンした状態でsonobuoyを実行し、パスできればよいのではないかと思ったが、結果的には上手くいかなかった。
理由は、ダウンしているノードがあるとそもそもsonobuoyの実行に失敗してしまうため。
Masterノード1台ダウン上程でsonobuoyを実行したところ、以下のようにRESULTがfailedになる。
# ./sonobuoy status
PLUGIN STATUS RESULT COUNT
e2e complete failed 1
systemd-logs complete passed 5
systemd-logs failed failed 1
Sonobuoy has completed. Use `sonobuoy retrieve` to get results.
結果を見ると、そもそもe2eテスト自体に失敗しているように見える。
# results=$(./sonobuoy retrieve) # ./sonobuoy results $results Plugin: e2e Status: failed Total: 1 Passed: 0 Failed: 1 Skipped: 0 Failed tests: BeforeSuite Plugin: systemd-logs Status: failed Total: 6 Passed: 5 Failed: 1
詳細な結果レポートを見てみると、ダウンしているノードがあることが原因の模様。
# less plugins/e2e/results/global/e2e.log
(略)
Apr 10 09:17:57.193: INFO: Condition Ready of node dev-k8s-001 is false, but Node is tainted by NodeController with [{node-role.kubernetes.io/master NoSchedule <nil>} {node.kubernetes.io/unreachable NoSchedule 2020-04-10 09:11:59 +0000 UTC} {node.kubernetes.io/unreachable NoExecute 2020-04-10 09:12:04 +0000 UTC}]. Failure
(略)
Apr 10 09:47:57.529: FAIL: Unexpected error:
<*errors.errorString | 0xc00005b970>: {
s: "timed out waiting for the condition",
}
timed out waiting for the condition
occurred
Failure [1800.654 seconds]
(略)
まとめ
- kubeadmでKubernetes HAクラスタを構築できた。 また、Masterノードが3台中1台ダウンしても、K8sクラスタとして正常に使用できることを確認した。
- 今回は検証のため、LBノードがSPOFになっている。
本番環境で使うためにはLBノードの冗長化や、その他もろもろの検討(ノード障害後のPodの偏りの解消方法等)が必要。
AWS CodeCommitリポジトリへのアクセスを除きMFA強制するIAMポリシー
AWSのIAMユーザを払い出した際に、不正アクセスのリスク低減のためMFA(多要素認証)の設定をしてほしいが、設定したかの確認が面倒だし、中々やってくれないといったケースがある。
そのような場合、以下ドキュメントのようにMFAを強制するIAMポリシーを割り当てることが有効。
docs.aws.amazon.com
ただし、このIAMポリシーを使った場合、CodeCommitのリポジトリへのアクセスにもMFAが必要となる。
git-remote-codecommitやAWS CLI 認証情報ヘルパーを使えばMFAを使ってリポジトリへアクセスできるが、環境やアクセス要件によってはこれらが使用できない場合もある。
その場合は、IAMポリシーを変更することでCodeCommitリポジトリへのアクセスのみMFA強制の対象外とすることができる。
その設定をした際のメモを記載する。
実施内容
CodeCommitへのアクセスに必要なアクションを許可する
前述したドキュメントに従ってIAMポリシーを作成すると、DenyAllExceptListedIfNoMFAステートメントのNotActionに「MFA を使用していない場合に許可する操作」が記載されている。
ここに、CodeCommitリポジトリの操作に必要な以下アクションを追加する。
- codecommit:GitPull
- codecommit:GitPush
- kms:Encrypt
- kms:Decrypt
- kms:ReEncrypt
- kms:GenerateDataKey
- kms:GenerateDataKeyWithoutPlaintext
- kms:DescribeKey
※KMS関連アクションも追加しているのは、CodeCommitへのアクセス時にKMSも使用されているため。
エイリアス名「aws/codecommit」のキーに対する上記KMS関連アクションを許可する必要がある。
詳細は以下リンク参照。
docs.aws.amazon.com
編集後のDenyAllExceptListedIfNoMFAステートメントは以下。
{
"Sid": "DenyAllExceptListedIfNoMFA",
"Effect": "Deny",
"NotAction": [
"iam:CreateVirtualMFADevice",
"iam:EnableMFADevice",
"iam:GetUser",
"iam:ListMFADevices",
"iam:ListVirtualMFADevices",
"iam:ResyncMFADevice",
"sts:GetSessionToken",
"codecommit:GitPull",
"codecommit:GitPush",
"kms:Encrypt",
"kms:Decrypt",
"kms:ReEncryptFrom",
"kms:ReEncryptTo",
"kms:GenerateDataKey",
"kms:GenerateDataKeyWithoutPlaintext",
"kms:DescribeKey"
],
"Resource": "*",
"Condition": {
"BoolIfExists": {
"aws:MultiFactorAuthPresent": "false"
}
}
},
KMS関連アクションの許可対象リソースを制限する
編集したDenyAllExceptListedIfNoMFAステートメントはResourceが「*」なので、このままだとKMS関連アクションが全てのキーに対してMFAなしで実行できてしまう。
そのため、 以下のようにaws/codecommit キー以外に対する kms関連アクションの Deny 設定を追加する。
{
"Sid": "DenyKMSExceptListedIfNoMFA",
"Effect": "Deny",
"Action": [
"kms:Encrypt",
"kms:Decrypt",
"kms:ReEncryptFrom",
"kms:ReEncryptTo",
"kms:GenerateDataKey",
"kms:GenerateDataKeyWithoutPlaintext",
"kms:DescribeKey"
],
"Resource": "*",
"Condition": {
"ForAnyValue:StringNotEquals": {
"kms:ResourceAliases": [
"alias/aws/codecommit"
]
},
"BoolIfExists": {
"aws:MultiFactorAuthPresent": "false"
}
}
}
※エイリアス指定でKMSキーへのアクセスを制御するには「kms:ResourceAliases」を使う。詳細は以下参照。
※ちなみに以下の書き方でもよい。
NotResourceにKMSキーのARNを記載する必要があるのが嫌だったので、今回はエイリアス名の記載だけでよい上記の書き方を採用した。
{
"Sid": "DenyKMSExceptListedIfNoMFA",
"Effect": "Deny",
"Action": [
"kms:Encrypt",
"kms:Decrypt",
"kms:ReEncryptFrom",
"kms:ReEncryptTo",
"kms:GenerateDataKey",
"kms:GenerateDataKeyWithoutPlaintext",
"kms:DescribeKey"
],
"NotResource": [
"arn:aws:kms:*:*:alias/aws/codecommit",
"{エイリアス名が「aws/codecommit」なKMSキーのARN}"
],
"Condition": {
"BoolIfExists": {
"aws:MultiFactorAuthPresent": "false"
}
}
}
最終的なIAMポリシー
最終的なIAMポリシーは以下のようになる。
このIAMポリシーをIAMユーザ or IAMユーザが所属するIAMグループに割り当てることで、「MFA設定するまで、MFAの設定とCodeCommitの操作以外できない」という挙動にすることができる。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowViewAccountInfo",
"Effect": "Allow",
"Action": [
"iam:GetAccountPasswordPolicy",
"iam:ListVirtualMFADevices"
],
"Resource": "*"
},
{
"Sid": "AllowManageOwnPasswords",
"Effect": "Allow",
"Action": [
"iam:ChangePassword",
"iam:GetUser"
],
"Resource": "arn:aws:iam::*:user/${aws:username}"
},
{
"Sid": "AllowManageOwnAccessKeys",
"Effect": "Allow",
"Action": [
"iam:CreateAccessKey",
"iam:DeleteAccessKey",
"iam:ListAccessKeys",
"iam:UpdateAccessKey"
],
"Resource": "arn:aws:iam::*:user/${aws:username}"
},
{
"Sid": "AllowManageOwnSigningCertificates",
"Effect": "Allow",
"Action": [
"iam:DeleteSigningCertificate",
"iam:ListSigningCertificates",
"iam:UpdateSigningCertificate",
"iam:UploadSigningCertificate"
],
"Resource": "arn:aws:iam::*:user/${aws:username}"
},
{
"Sid": "AllowManageOwnSSHPublicKeys",
"Effect": "Allow",
"Action": [
"iam:DeleteSSHPublicKey",
"iam:GetSSHPublicKey",
"iam:ListSSHPublicKeys",
"iam:UpdateSSHPublicKey",
"iam:UploadSSHPublicKey"
],
"Resource": "arn:aws:iam::*:user/${aws:username}"
},
{
"Sid": "AllowManageOwnGitCredentials",
"Effect": "Allow",
"Action": [
"iam:CreateServiceSpecificCredential",
"iam:DeleteServiceSpecificCredential",
"iam:ListServiceSpecificCredentials",
"iam:ResetServiceSpecificCredential",
"iam:UpdateServiceSpecificCredential"
],
"Resource": "arn:aws:iam::*:user/${aws:username}"
},
{
"Sid": "AllowManageOwnVirtualMFADevice",
"Effect": "Allow",
"Action": [
"iam:CreateVirtualMFADevice",
"iam:DeleteVirtualMFADevice"
],
"Resource": "arn:aws:iam::*:mfa/${aws:username}"
},
{
"Sid": "AllowManageOwnUserMFA",
"Effect": "Allow",
"Action": [
"iam:DeactivateMFADevice",
"iam:EnableMFADevice",
"iam:ListMFADevices",
"iam:ResyncMFADevice"
],
"Resource": "arn:aws:iam::*:user/${aws:username}"
},
{
"Sid": "DenyAllExceptListedIfNoMFA",
"Effect": "Deny",
"NotAction": [
"iam:CreateVirtualMFADevice",
"iam:EnableMFADevice",
"iam:GetUser",
"iam:ListMFADevices",
"iam:ListVirtualMFADevices",
"iam:ResyncMFADevice",
"sts:GetSessionToken",
"codecommit:GitPull",
"codecommit:GitPush",
"kms:Encrypt",
"kms:Decrypt",
"kms:ReEncryptFrom",
"kms:ReEncryptTo",
"kms:GenerateDataKey",
"kms:GenerateDataKeyWithoutPlaintext",
"kms:DescribeKey"
],
"Resource": "*",
"Condition": {
"BoolIfExists": {
"aws:MultiFactorAuthPresent": "false"
}
}
},
{
"Sid": "DenyKMSExceptListedIfNoMFA",
"Effect": "Deny",
"Action": [
"kms:Encrypt",
"kms:Decrypt",
"kms:ReEncryptFrom",
"kms:ReEncryptTo",
"kms:GenerateDataKey",
"kms:GenerateDataKeyWithoutPlaintext",
"kms:DescribeKey"
],
"Resource": "*",
"Condition": {
"ForAnyValue:StringNotEquals": {
"kms:ResourceAliases": [
"alias/aws/codecommit"
]
},
"BoolIfExists": {
"aws:MultiFactorAuthPresent": "false"
}
}
}
]
}
補足
CodeCommitへMFAを使ってアクセスする方法
CodeCommitへMFAを使ってアクセスするには、git-remote-codecommitかAWS CLI 認証情報ヘルパーを使う必要がある。 ※このページに「CodeCommit への一時アクセスまたはフェデレーティッドアクセスに対して推奨されるアプローチは git-remote-codecommit を設定すること」とあるので、git-remote-codecommitの方が推奨されている模様。
それぞれの具体的な設定手順は以下を参照。
- git-remote-codecommit
docs.aws.amazon.com
- AWS CLI 認証情報ヘルパー
docs.aws.amazon.com
どちらの接続方式も、get-session-token コマンドを使用してMFA認証して、コマンド結果に含まれる一時的な認証情報を用いて、CodeCommit へアクセスする。
アクセス方法は以下を参照。
aws.amazon.com
IAMユーザー払い出し時の注意点
ユーザ作成時は「パスワードのリセットが必要」にチェックを入れない
IAMユーザ作成時によくやるのが、「パスワードのリセットが必要」にチェックを入れて、初回ログイン時にユーザにパスワードリセットを強制する設定。
しかし、本ページで紹介したIAMポリシーを割り当てたユーザーは、MFA認証でログインしない限りパスワード変更できないため、MFA設定前の初回ログイン時にはパスワードリセットする権限がない。
そのため、初回ログイン時に「パスワードリセットしないと先に進めないのに、リセット権限がない」という状況に陥り、何もできなくなってしまう。
なので、IAMユーザ作成時には「パスワードのリセットが必要」にチェックを入れず、2回目以降のログイン時にパスワードを変更するようユーザに伝える必要がある。
※IAMポリシーを緩めれば初回ログインでパスワードリセットさせることは可能だが、このドキュメントに「IAM ではこのようなアクセス許可をお勧めしません。ユーザーが MFA なしで自分のパスワードを変更できるようにすると、セキュリティ上のリスクが生じる可能性があります。」と記載してあるので、やらない方が良いと思う。
MFA設定画面までの行き方に注意
AWSのMFA有効化手順にはIAMの画面からナビゲーションペインの「ユーザ」をクリックすると記載されている。
しかし、本ページのポリシーを適用しているとMFA認証でログインするまではユーザの一覧画面を開く権限がなく、エラーとなってしまう。
そのため、自分のユーザの画面を開くためには、右上のユーザー名から「セキュリティ認証情報」をクリックする必要がある。
新規ユーザを作成した場合はこの手順についてもユーザに伝える。
参考文献
【NETGEAR M4300-52G】ポートVLANとLAG(リンクアグリゲーション)を設定する
NETGEARのネットワークスイッチ「M4300-52G」のポートVLANとLAG(リンクアグリゲーション)を設定した時のメモ。
GUI(ブラウザアクセスする管理画面)があるようなので、これを使って設定をした。
環境
・NETGEAR M4300-52G
実施内容
ログイン
ユーザ、パスワードを入力して「Login」をクリックする。
ポートVLAN設定
「Switching」→「VLAN」→「VLAN Membership」と進むと、以下画面になる。
ポートVLANを設定したいVLAN IDをプルダウンから選択して、対象のポートをクリックして「U」と表示させる。
※以下の例では、Unit1の13ポート、14ポートにVLAN200をで設定している。
その後、画面右上の「Apply」をクリックする。

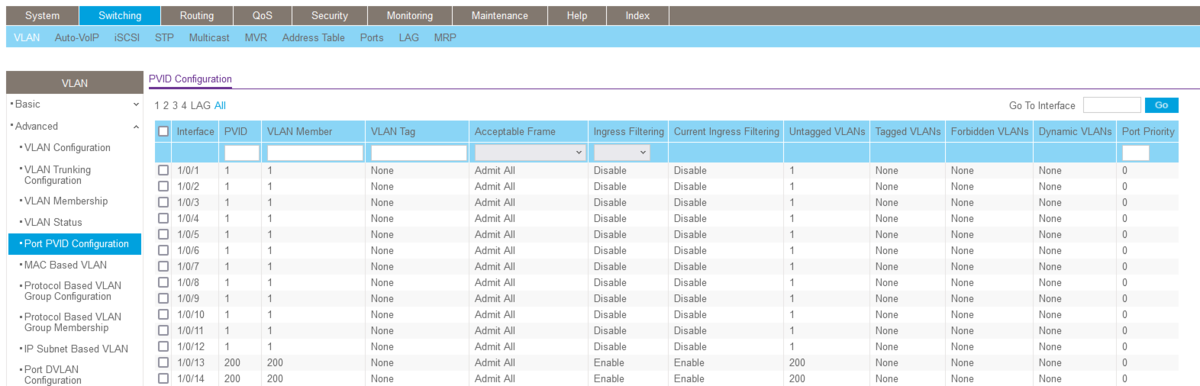
ポートVLANが設定されたことを確認する。
「Switching」→「VLAN」→「Port PVID Configuration」と進むと、以下画面になる。
Unit1の13ポート、14ポート(interface列が1/0/13、1/0/14の行)を確認すると、PVID、VLAN Memberの列にVLAN200が表示されていることが確認できる。
この状態になっていればOK。
LAG(リンクアグリゲーション)設定
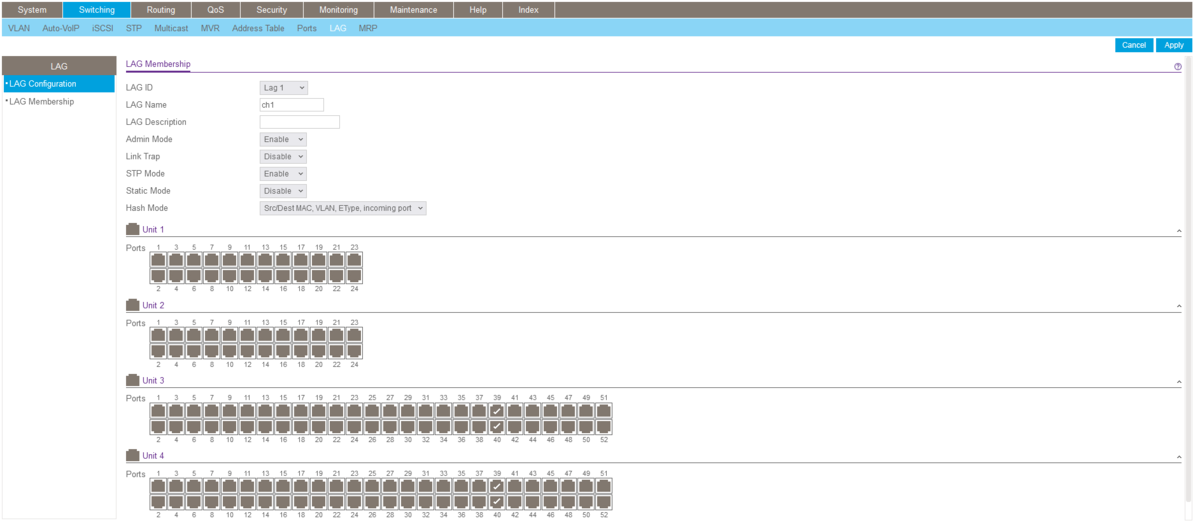
LAGの設定をする。
「Switching」→「LAG」→「LAG Configuration」と進むと、以下画面になる。
今回はch1に設定してみる。
LAG Nameの列の「ch1」をクリックする。

必要であればLAGの各設定項目をプルダウンを操作して変更する。
以下画像に表示されているのがデフォルトの値。
Static Modeは、対向ポートの設定と同じにする必要があるので、確認して設定すること。
今回は、対向機器のLAGポートでLACPを使用しているため、Static Modeを「Disable」としている。
LAGを設定するポートをクリックして、チェックマークを付ける。
※以下の例では、Unit3の39、40ポート、Unit4の39、40ポートの4つのポートにLAGを設定している。
その後、画面右上の「Apply」をクリックする。
LAG設定を確認する。
「Switching」→「LAG」→「LAG Configuration」と進み、Configured Portsに設定したポート番号が表示されていることを確認できればOK。

参考文献
【HPE 6125G Blade Switch】DHCPを無効にする
HPE 6125G Blade SwitchのあるポートでDHCPが意図せず有効になっていたので、無効にした。 その際のメモ。
環境
・機種:HPE 6125G Blade Switch ・ホスト名:DEV_SWITCH
実施内容
特権モードになる
<DEV_SWITCH> super
configurationモードに入る
<DEV_SWITCH> system-view
対象のポート(この例では0/0/0ポート)の現在の設定を見る。 DHCPでIPが割り当てられていることが分かる。
[DEV_SWITCH] display interface M-Ethernet0/0/0
M-Ethernet0/0/0 current state: UP
Line protocol current state: UP
Description: M-Ethernet0/0/0 Interface
The Maximum Transmit Unit is 1500
Internet Address is 192.168.10.11/24, acquired via DHCP
IP Packet Frame Type: PKTFMT_ETHNT_2, Hardware Address: 40b9-3c9d-cb3d
IPv6 Packet Frame Type: PKTFMT_ETHNT_2, Hardware Address: 40b9-3c9d-cbb9
Media type is twisted pair, loopback not set
Port hardware type is 100_BASE_T
100Mbps-speed mode , full-duplex mode
input: 543303 packets, 3905093486 bytes
1444054 broadcasts, 1911279 multicasts
input: - input errors, 0 runts, 0 giants, - throttles, 0 CRC
0 frame,- overruns, 0 aborts,- ignored,- parity errors
output: 765509 packets, 135572605 bytes
275688 broadcasts, 0 multicasts
output: - output errors, - underruns, - buffer failures
0 aborts, 0 deferred, 0 collisions, 0 late collisions
- lost carrier,- no carrier
0/0/0ポートの設定に入る
[DEV_SWITCH] interface M-Ethernet0/0/0
[DEV_SWITCH-M-Ethernet0/0/0] undo ip address dhcp-alloc [DEV_SWITCH-M-Ethernet0/0/0] undo ipv6 address auto [DEV_SWITCH-M-Ethernet0/0/0] undo ipv6 address dhcp-alloc
ポートの設定が変わったことを確認する。
[DEV_SWITCH-M-Ethernet0/0/0] display interface M-Ethernet0/0/0
M-Ethernet0/0/0 current state: UP
Line protocol current state: UP
Description: M-Ethernet0/0/0 Interface
The Maximum Transmit Unit is 1500
Internet protocol processing : disabled
IP Packet Frame Type: PKTFMT_ETHNT_2, Hardware Address: 40b9-3c9d-cb3d
IPv6 Packet Frame Type: PKTFMT_ETHNT_2, Hardware Address: 40b9-3c9d-cbb9
Media type is twisted pair, loopback not set
Port hardware type is 100_BASE_T
100Mbps-speed mode , full-duplex mode
input: 543350 packets, 3905106169 bytes
1444081 broadcasts, 1911295 multicasts
input: - input errors, 0 runts, 0 giants, - throttles, 0 CRC
0 frame,- overruns, 0 aborts,- ignored,- parity errors
output: 765511 packets, 135573047 bytes
275689 broadcasts, 0 multicasts
output: - output errors, - underruns, - buffer failures
0 aborts, 0 deferred, 0 collisions, 0 late collisions
- lost carrier,- no carrier
現在の設定全体を確認する
[DEV_SWITCH-M-Ethernet0/0/0] display current-configuration
saved-configuration(スイッチ起動時に読み込まれる設定)に変更内容を保存する
[DEV_SWITCH-M-Ethernet0/0/0] save The current configuration will be written to the device. Are you sure? [Y/N]:y Please input the file name(*.cfg)[flash:/config.cfg] (To leave the existing filename unchanged, press the enter key): flash:/config.cfg exists, overwrite? [Y/N]:y Validating file. Please wait.... The current configuration is saved to the active main board successfully. Configuration is saved to device successfully.
saved-configurationを表示し、変更が反映されたこと(current-configurationと同じ内容になっていること)を確認する。
[DEV_SWITCH-M-Ethernet0/0/0] display saved-configuration
ログアウトする
[DEV_SWITCH-M-Ethernet0/0/0] quit [DEV_SWITCH] quit <DEV_SWITCH> quit
RockyLinux8のkernelをアップグレードする
RockyLinux8のカーネルを、2022年7月現在の最新安定版である5.18にアップグレードしたときのメモを残しておく。
環境
・RockyLinux8.6(4.18.0-372.9.1→5.18.9-1)
実施内容
OSとカーネルバージョンの確認
# cat /etc/redhat-release Rocky Linux release 8.6 (Green Obsidian) # uname -r 4.18.0-372.9.1.el8.x86_64
更新に利用できるパッケージを確認する
# dnf check-update
パッケージを更新する
# dnf update
デフォルトのリポジトリには最新版のカーネルがないため、ELRepoを追加する
# dnf install https://www.elrepo.org/elrepo-release-8.el8.elrepo.noarch.rpm # rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
カーネルを最新版にアップグレードする
# dnf --enablerepo=elrepo-kernel install kernel-ml kernel-ml-devel kernel-ml-headers
OSを再起動する
# reboot
再起動後に、カーネルのバージョンが上がっていることを確認する
# uname -r 5.18.9-1.el8.elrepo.x86_64
AWS 同一ECSクラスタ内で、ECSインスタンスを特定の利用者(ECSタスク)に占有させる(Terraform使用)
AWS ECSで、クラスタークエリ言語を使ってECSインスタンスにカスタム属性を付与することで、ECSタスクの実行インスタンスを制御したときのメモ。
環境
・Terraform:1.0.8
やりたいこと
以下を実現したい。
- ECSタスクを実行するときだけ、必要なECSインスタンスを起動し、ECSタスクを実行したい。
- とりあえずはECSインスタンスのオートスケールは不要。タスク実行の前後に、必要な台数のECSインスタンスを追加、削除する。
- 単一のECSクラスタに対して、複数人が同様の作業を行う可能性がある。同時実行された場合に、自分が起動したECSインスタンスは他の人に使われたくない(占有したい)。
実現方法の検討
方針
KubernetesでいうNode Affinity的な機能がECSにもあれば実現出来そうだな、と思って調査したところ、以下ページににそれらしい記述を発見した。 aws.amazon.com
「Constraints」の章の「Member of」の説明に、ECSタスクが配置されるECSインスタンスを、ある属性を持つECSインスタンスに制限する例が載っている。 このページの例だとインスタンスやAZといった属性を使っているが、クラスタークエリ言語というのを使えばカスタム属性を使うこともできそう。
ECSインスタンスに属性を付与する方法
以下に記載がある。 ・既存のECSインスタンスに属性を付与する方法。 docs.aws.amazon.com ・ECS コンテナエージェントの設定で、ECSインスタンスに属性を付与する方法。 docs.aws.amazon.com
タスクの配置先を、特定の属性を持つECSインスタンスに制限する方法
タスク実行(runTask)時に、配置制約を設定すればよい。詳細は以下。 ・配置制約の記載例。 docs.aws.amazon.com ・配置制約内に記載するクラスタークエリ言語の構文。 docs.aws.amazon.com
実現方法まとめ
以下の方法で、やりたいことが実現できそう。
・ECSインスタンスにユーザ単位でユニークなカスタム属性をインスタンスに付与する。
・インスタンス作成時に付与したいので、ユーザーデータを使ってECSコンテナエージェントの設定を行う。
・タスク起動時に、配置先を上記カスタム属性を持つECSインスタンスに制限してタスクを起動することにする。
※上記のページ中にタスクグループ(task:groupという属性)を使う例が登場する。
一見これでも実現出来そうだが、これはある既にあるタスクが配置されている場合に、そのタスクと同じECSインスタンスにタスクを配置したいときに使うものであり、既存のタスクが存在しない場合にECSインスタンスの指定ができない。
(ECSインスタンスのAffinityではなく、ECSタスクのAffinity。)
以下にもそのような記載がある。
stackoverflow.com
そのため、今回やりたいことには合わない。
動作確認環境の構築
その後、以下を実行するTerrformコードを作成し、構築を行った。
- ECSで使用するVPC、セキュリティグループ、IAMロールの作成
- ユーザーデータを使って「group:001」というカスタム属性を付与したECSインスタンス(インスタンス名:ec2_001)の作成
- ユーザーデータを使って「group:002」というカスタム属性を付与したECSインスタンス(インスタンス名:ec2_002)の作成
- ECSクラスタの作成
- 動作確認用のECSタスク定義(「sleep 600」を実行するだけのタスク)の作成
※以下のTerraform Moduleを使用している。
- vpc
- security-group
- iam
- ec2-instance
- ecs
- ecs-container-definition
使用したTerraformコード
# VPCとサブネットの作成
module "vpc" {
source = "terraform-aws-modules/vpc/aws"
version = "3.7.0"
name = "test-vpc" # VPC名
cidr = "10.0.0.0/16" # VPCのCIDR
azs = ["ap-northeast-1a", "ap-northeast-1c"] # サブネットを作成するAZ
private_subnets = ["10.0.32.0/24", "10.0.33.0/24"] # プライベートサブネットのCIDR
public_subnets = ["10.0.16.0/24", "10.0.17.0/24"] # パブリックサブネットのCIDR
enable_nat_gateway = true # NATゲートウェイを作成する
enable_vpn_gateway = false # VPNゲートウェイを作成しない
enable_dns_hostnames = true # DNSホスト名を有効にする
}
# ECSインスタンス用セキュリティグループの作成
module "ecs_instance_sg" {
source = "terraform-aws-modules/security-group/aws"
version = "4.3.0"
name = "test-sg-ecs" # セキュリティグループ名
description = "test-sg-ecs" # セキュリティグループ説明
vpc_id = module.vpc.vpc_id # セキュリティグループを作成するVPC
egress_with_cidr_blocks = [ # アウトバウンドルール
{
rule = "all-all"
cidr_blocks = "0.0.0.0/0"
},
]
ingress_with_self = [ # インバウンドルール
{
rule = "all-all"
},
]
}
# ECSインスタンス用IAMロールの作成
module "iam_assumable_role_ecs" {
source = "terraform-aws-modules/iam/aws//modules/iam-assumable-role"
version = "4.6.0"
trusted_role_services = [
"ec2.amazonaws.com" # 信頼されたエンティティにEC2を設定
]
create_role = true # IAMロールを作成する
create_instance_profile = true # IAMロールのインスタンスプロファイルを作成する
role_name = "test-role-ecs-instance" # IAMロール名
role_requires_mfa = false # MFA必須にしない
custom_role_policy_arns = [
"arn:aws:iam::aws:policy/service-role/AmazonEC2ContainerServiceforEC2Role" # ECSインスタンス用に用意されているIAMポリシーを設定
]
}
# ECSタスク用IAMロールの作成
module "iam_assumable_role_ecstask" {
source = "terraform-aws-modules/iam/aws//modules/iam-assumable-role"
version = "4.6.0"
trusted_role_services = [
"ecs-tasks.amazonaws.com" # 信頼されたエンティティにECSタスクを設定
]
create_role = true # IAMロールを作成する
role_name = "test-role-ecs-task" # IAMロール名
role_requires_mfa = false # MFA必須にしない
custom_role_policy_arns = [
"arn:aws:iam::aws:policy/AWSXRayDaemonWriteAccess" # X-RAYへ情報を送信するためのIAMポリシーを設定
]
}
# ECS GPU-optimized AMI
data "aws_ami" "amazon_linux_ecs" {
most_recent = true
owners = ["amazon"]
filter {
name = "name"
values = ["amzn2-ami-ecs-hvm-2.0.20220411-x86_64-ebs"]
}
filter {
name = "owner-alias"
values = ["amazon"]
}
}
# ECSインスタンス用ユーザーデータ
data "template_file" "user_data_001" {
template = file("./templates/user-data.sh")
vars = {
cluster_name = "test-ecs-cluster"
group_id = "001"
}
}
data "template_file" "user_data_002" {
template = file("./templates/user-data.sh")
vars = {
cluster_name = "test-ecs-cluster"
group_id = "002"
}
}
# ECSインスタンス(group:001)
module "ec2_001" {
source = "terraform-aws-modules/ec2-instance/aws"
version = "3.2.0"
name = "ecs-instance-001"
ami = data.aws_ami.amazon_linux_ecs.id
instance_type = "t2.micro"
availability_zone = element(module.vpc.azs, 0)
subnet_id = element(module.vpc.private_subnets, 0)
vpc_security_group_ids = [module.ecs_instance_sg.security_group_id]
key_name = "test-ec2-key"
iam_instance_profile = module.iam_assumable_role_ecs.iam_instance_profile_name
user_data = data.template_file.user_data_001.rendered
enable_volume_tags = true
root_block_device = [
{
encrypted = false
volume_type = "gp2"
volume_size = 30
},
]
}
# ECSインスタンス(group:002)
module "ec2_002" {
source = "terraform-aws-modules/ec2-instance/aws"
version = "3.2.0"
name = "ecs-instance-002"
ami = data.aws_ami.amazon_linux_ecs.id
instance_type = "t2.micro"
availability_zone = element(module.vpc.azs, 0)
subnet_id = element(module.vpc.private_subnets, 0)
vpc_security_group_ids = [module.ecs_instance_sg.security_group_id]
key_name = "test-ec2-key"
iam_instance_profile = module.iam_assumable_role_ecs.iam_instance_profile_name
user_data = data.template_file.user_data_002.rendered
enable_volume_tags = true
root_block_device = [
{
encrypted = false
volume_type = "gp2"
volume_size = 30
},
]
}
# ECSクラスタの作成
module "ecs" {
source = "terraform-aws-modules/ecs/aws"
version = "3.4.0"
name = "test-ecs-cluster" # ECSクラスタ名
container_insights = true # Container Insightsを有効にする
}
# リージョン名
data "aws_region" "now" {}
#ECSタスク用ロググループの作成
resource "aws_cloudwatch_log_group" "log_ecstask_test" {
name = "/ecs/test-ecstask" # ロググループ名
retention_in_days = 1 # 保存期間(日)
}
## ECSタスク定義に使うコンテナ定義JSONの生成
### APコンテナ
module "test_ap_container" {
source = "cloudposse/ecs-container-definition/aws"
version = "0.58.1"
container_name = "ap" # コンテナ名
container_image = "amazonlinux:2" # コンテナイメージ
command = ["sh", "-c", "sleep 600"] # 実行コマンド
container_memory = 982 # ハードメモリ制限(MiB)
container_memory_reservation = 982 # ソフトメモリ制限(MiB)
container_cpu = 1024 # 予約するCPUユニット数
essential = true # 基本パラメータ。trueの場合は、このコンテナの失敗によりタスクが停止する。
log_configuration = { # ログ出力設定
logDriver = "awslogs"
options = {
"awslogs-group" = "/ecs/test-ecstask"
"awslogs-region" = data.aws_region.now.name
"awslogs-stream-prefix" = "ecs"
}
secretOptions = null
}
}
## ECSタスク定義
resource "aws_ecs_task_definition" "test" {
# 注意:applyを実行するたびに、常に新しいリビジョンに更新してしまうため、lifecycleで更新されないようにしている
# このタスク定義を更新したい場合のみ、lifecycle部分をコメントアウトすること
# https://github.com/hashicorp/terraform-provider-aws/issues/258
lifecycle {
ignore_changes = all
}
family = "test-ecstask" # ECSタスク名
container_definitions = jsonencode([ # ECSコンテナ定義JSONを設定
module.test_ap_container.json_map_object
])
task_role_arn = module.iam_assumable_role_ecstask.iam_role_arn # ECSタスクロールを指定
cpu = 1024 # タスクCPUユニット数
memory = 982 # タスクメモリ(MiB)
requires_compatibilities = ["EC2"] # 互換性が必要な起動タイプ
network_mode = "bridge" # ネットワークモード
}
「./templates/user-data.sh」の中身は以下。
#!/bin/bash
echo ECS_CLUSTER=${cluster_name} >> /etc/ecs/ecs.config
echo ECS_INSTANCE_ATTRIBUTES={\"group_id\": \"${group_id}\"} >> /etc/ecs/ecs.config
動作確認
ECSインスタンスの属性を確認する
何らかの方法で作成したECSインスタンスにログインして、ECSコンテナエージェントのconfigを確認する。 ※今回は、ECSインスタンスに接続できる踏み台EC2インスタンスを作成し、ECSインスタンスにsshして確認した。 - ec2_001のconfig
# cat /etc/ecs/ecs.config
ECS_CLUSTER=test-ecs-cluster
ECS_INSTANCE_ATTRIBUTES={"group_id": "001"}
- ec2_002のconfig
# cat /etc/ecs/ecs.config
ECS_CLUSTER=test-ecs-cluster
ECS_INSTANCE_ATTRIBUTES={"group_id": "002"}
→それぞれ想定の属性が設定されている。
また、マネジメントコンソールのECSインスタンス表示画面から、インスタンスに属性が付与されていることを確認できる。

※カスタム属性はデフォルトでは表示されていない。
上記ページの歯車マークをクリックすると、以下のように表示する内容を変更できる。

配置制約を指定してタスクを実行する
AWSCLIを使って、「group_idが001」という配置制約でタスクを1つ実行してみる。
$ ECS_CLUSTER="ECSクラスタのARN"
$ TASK="test-ecstask:1"
$ COUNT=1
$ PLACEMENT_CONSTRAINTS="type=memberOf,expression=attribute:group_id == 001"
$ aws --profile stg-user ecs run-task --cluster ${ECS_CLUSTER} --task-definition ${TASK} --count ${COUNT} --placement-constraints "${PLACEMENT_CONSTRAINTS}"
想定通り、「group_idが001」であるec2_001インスタンスで起動した。

AWSCLIを使って、「group_idが002」という配置制約でタスクを1つ実行してみる。
$ ECS_CLUSTER="ECSクラスタのARN"
$ TASK="test-ecstask:1"
$ COUNT=1
$ PLACEMENT_CONSTRAINTS="type=memberOf,expression=attribute:group_id == 002"
$ aws --profile stg-user ecs run-task --cluster ${ECS_CLUSTER} --task-definition ${TASK} --count ${COUNT} --placement-constraints "${PLACEMENT_CONSTRAINTS}"
想定通り、「group_idが002」であるec2_002インスタンスで起動した。

AWSCLIを使って、「group_idが003」という配置制約でタスクを1つ実行してみる。
$ ECS_CLUSTER="ECSクラスタのARN"
$ TASK="test-ecstask:1"
$ COUNT=1
$ PLACEMENT_CONSTRAINTS="type=memberOf,expression=attribute:group_id == 003"
$ aws --profile stg-user ecs run-task --cluster ${ECS_CLUSTER} --task-definition ${TASK} --count ${COUNT} --placement-constraints "${PLACEMENT_CONSTRAINTS}"
「group_idが003」という制約に該当するECSインスタンスは存在しないため、以下のように「MemberOf placement constraint unsatisfied」というエラーとなった。
{
"tasks": [],
"failures": [
{
"arn": "arn:aws:ecs:ap-northeast-1:900501247601:container-instance/1d44d64291814d1ab4997169b4172d7c",
"reason": "MemberOf placement constraint unsatisfied."
},
{
"arn": "arn:aws:ecs:ap-northeast-1:900501247601:container-instance/530839e48ef84fdead06b208d91946a2",
"reason": "MemberOf placement constraint unsatisfied."
}
]
}
ちなみに、以下のように配置制約を指定しないで2タスク実行すると、ec2_001とec2_002両方で実行される。 ECSインスタンスの属性はあくまで配置制約を指定したときに使われるだけなので、「配置制約でgroup_idを指定していないタスクは配置されない」といったことにはならない。
$ ECS_CLUSTER="ECSクラスタのARN"
$ TASK="test-ecstask:1"
$ COUNT=2
$ aws --profile stg-user ecs run-task --cluster ${ECS_CLUSTER} --task-definition ${TASK} --count ${COUNT}
まとめ
- カスタム属性と配置制約を活用することで、タスクの配置先として特定のECSインスタンスを指定できる。
- これによって、同一のECSクラスタ内を複数人で利用する際に、自分が作成したECSインスタンスを占有することが可能。
(配置制約を使わずにタスクを起動されると占有できないので、必ず配置制約を使用するという運用ルールは必要。)
おまけ:ECSクラスタのスケーリングについて
・以前の記事で検証したオートスケールECSクラスタと組み合わせて、配置制約に当てはまるECSインスタンスの台数をスケールできないか。
→配置制約に当てはまるECSインスタンスのみ追加するといった制御はできない。
利用者の数だけAuto Scalingグループとキャパシティプロバイダを事前に定義しておき、ECSクラスタに設定すれば、各配置制約を満たすECSインスタンスを自動的に追加させることはできる。
しかし、スケールの基準に用いられる指標はあくまでタスク数であり、そのタスクがどのような配置制約を指定しているかは考慮されない。
・以前の記事で作成したECSクラスタでは、インスタンスに空きが無い状態でタスクを実行すると、タスクの状態はpendingになり、インスタンス台数がスケールした後に処理されていた。
今回作成したECSクラスタでは、インスタンスに空きが無い状態でタスクを実行すると、タスクの状態はpendingにならずに即座に「"reason": "RESOURCE:CPU"」などリソース不足が理由でエラーになる。
この挙動の違いはどこの設定に依存するか気になったので、AWSサポートに問合せたところ、以下の回答だった。
- ECS タスクの起動にキャパシティープロバイダー戦略が選択されるか、起動タイプが選択されるかによって、タスクを起動可能なコンテナインスタンスが存在しない場合の挙動が変わる。
- ECSタスクの起動(RunTask API実行)時に、"capacityProviderStrategy" のプロパティを明示的に指定した場合、または "capacityProviderStrategy" および "launchType" の双方を指定せずデフォルトキャパシティープロバイダー戦略が自動的に使用される場合、起動されるタスクは PROVISIONING 状態となり、 Auto Scaling などにより使用可能なコンテナインスタンスが用意されるのを待つ動きとなる。
- ECSタスクの起動(RunTask API実行)時に、起動タイプ(EC2など)を指定した場合には、
"reason": "RESOURCE:CPU"などのメッセージにて API の呼び出し自体に失敗する挙動となる。 - ただし、キャパシティプロバイダを設定したECSクラスタに対して明示的に起動タイプ に "EC2" を指定して RunTask API を呼び出すことは、以下ページに「When you use cluster auto scaling, you must specify capacityProviderStrategy and not launchType.」と記載されているように非推奨。 docs.aws.amazon.com
AWS ECSクラスタをTerraformで構築する(EC2、Auto Scaling、GPU利用)
AWS ECS クラスター Auto Scaling (CAS)を活用したECSクラスタ(GPUインスタンス利用)を、Terraformを使って構築した。
環境
・Terraform:1.0.8
やりたいこと
以下を実現したい。
- イベントを契機にある処理をしたい。
- イベントの発生頻度、量は予想が困難。
- イベントが大量に発生した場合も、
処理を並列同時実行することでスループットを維持したい。 - 出来るだけコストを抑えたい。
- 「ある処理」にはGPUの利用が必要。
- 「ある処理」には15分以上かかる見込み。
必要な分だけスケール・課金ということなので、LambdaやECS(Fargate)を使いたくなるが、以下に記載した通り、今回の要件は実現できない。
ECS(EC2起動タイプ)であれば実現できそう。
- Lambda
→15分以上かかる処理には使用できず、GPUも利用できないため、不採用。 - ECS(Fargate起動タイプ) ※イベントを検知してECSタスクを起動する部分はLambdaでやる
→GPUを利用できないため、不採用。 - ECS(EC2起動タイプ) ※イベントを検知してECSタスクを起動する部分はLambdaでやる
→処理時間制限がなく、GPUも利用可能。
ECS クラスター Auto Scaling (CAS)を使えば、0台からのスケールも可能。
構築
以下を参考にECS Cluster Auto Scaling機能を試して概要を理解した。
その後、以下を実行するTerrformコードを作成し、構築を行った。
- ECSで使用するVPC、セキュリティグループ、IAMロールの作成
- ECS クラスター Auto Scaling (CAS)により0台からスケールし、かつGPUインスタンス(g4dn.xlarge)を使用するECSクラスタの作成
- 動作確認用のECSタスク定義の作成
※以下のTerraform Moduleを使用している。
使用したTerraformコード
# VPCとサブネットの作成
module "vpc" {
source = "terraform-aws-modules/vpc/aws"
version = "3.7.0"
name = "test-vpc" # VPC名
cidr = "10.0.0.0/16" # VPCのCIDR
azs = ["ap-northeast-1a", "ap-northeast-1c"] # サブネットを作成するAZ
private_subnets = ["10.0.32.0/24", "10.0.33.0/24"] # プライベートサブネットのCIDR
public_subnets = ["10.0.16.0/24", "10.0.17.0/24"] # パブリックサブネットのCIDR
enable_nat_gateway = true # NATゲートウェイを作成する
enable_vpn_gateway = false # VPNゲートウェイを作成しない
enable_dns_hostnames = true # DNSホスト名を有効にする
}
# ECSインスタンス用セキュリティグループの作成
module "ecs_instance_sg" {
source = "terraform-aws-modules/security-group/aws"
version = "4.3.0"
name = "test-sg-ecs" # セキュリティグループ名
description = "test-sg-ecs" # セキュリティグループ説明
vpc_id = module.vpc.vpc_id # セキュリティグループを作成するVPC
egress_with_cidr_blocks = [ # アウトバウンドルール
{
rule = "all-all"
cidr_blocks = "0.0.0.0/0"
},
]
ingress_with_self = [ # インバウンドルール
{
rule = "all-all"
},
]
}
# ECSインスタンス用IAMロールの作成
module "iam_assumable_role_ecs" {
source = "terraform-aws-modules/iam/aws//modules/iam-assumable-role"
version = "4.6.0"
trusted_role_services = [
"ec2.amazonaws.com" # 信頼されたエンティティにEC2を設定
]
create_role = true # IAMロールを作成する
create_instance_profile = true # IAMロールのインスタンスプロファイルを作成する
role_name = "test-role-ecs-instance" # IAMロール名
role_requires_mfa = false # MFA必須にしない
custom_role_policy_arns = [
"arn:aws:iam::aws:policy/service-role/AmazonEC2ContainerServiceforEC2Role" # ECSインスタンス用に用意されているIAMポリシーを設定
]
}
# ECSタスク用IAMロールの作成
module "iam_assumable_role_ecstask" {
source = "terraform-aws-modules/iam/aws//modules/iam-assumable-role"
version = "4.6.0"
trusted_role_services = [
"ecs-tasks.amazonaws.com" # 信頼されたエンティティにECSタスクを設定
]
create_role = true # IAMロールを作成する
role_name = "test-role-ecs-task" # IAMロール名
role_requires_mfa = false # MFA必須にしない
custom_role_policy_arns = [
"arn:aws:iam::aws:policy/AWSXRayDaemonWriteAccess" # X-RAYへ情報を送信するためのIAMポリシーを設定
]
}
# ECS GPU-optimized AMI
data "aws_ami" "amazon_linux_ecs" {
most_recent = true
owners = ["amazon"]
filter {
name = "name"
values = ["amzn2-ami-ecs-gpu-hvm-2.0.20210708-x86_64-ebs"]
}
filter {
name = "owner-alias"
values = ["amazon"]
}
}
# ECSインスタンス用ユーザーデータ
data "template_file" "user_data" {
template = file("./templates/user-data.sh")
vars = {
cluster_name = "test-ecs-cluster"
}
}
# 起動設定とAuto Scalingグループの作成
module "asg_g4dn" {
source = "terraform-aws-modules/autoscaling/aws"
version = "4.6.0"
# 起動設定
lc_name = "test-aslc-g4dn" # 起動設定の名前
use_lc = true # 起動設定を利用する
create_lc = true # 起動設定を作成する
image_id = data.aws_ami.amazon_linux_ecs.id # 「ECS GPU-optimized AMI」を使用する
instance_type = "g4dn.xlarge" # インスタンスタイプ
security_groups = [module.ecs_instance_sg.security_group_id] # セキュリティグループ
iam_instance_profile_name = module.iam_assumable_role_ecs.iam_instance_profile_arn # インスタンスにアタッチするIAMロール
user_data = data.template_file.user_data.rendered # ユーザーデータ
ebs_optimized = true # EBS最適化を有効
root_block_device = [ # ストレージ設定
{
delete_on_termination = true
encrypted = false
volume_size = "30"
volume_type = "gp2"
},
]
# Auto Scalingグループ
name = "test-asg-g4dn" # Auto Scalingグループの名前
vpc_zone_identifier = module.vpc.private_subnets # 起動するサブネット
health_check_type = "EC2" # ヘルスチェックのタイプ
min_size = 0 # 最小キャパシティ
max_size = 100 # 最大キャパシティ
wait_for_capacity_timeout = 0 # TerraformがAuto Scalingグループのインスタンスの作成を待機しないようにする
protect_from_scale_in = true # インスタンスのスケールイン保護を有効にする
}
# キャパシティプロバイダの作成
resource "aws_ecs_capacity_provider" "prov" {
name = "test-ecs-cp"
auto_scaling_group_provider {
auto_scaling_group_arn = module.asg_g4dn.autoscaling_group_arn # 使用するAuto ScalingグループのARN
managed_termination_protection = "ENABLED" # マネージドターミネーション保護を有効にする
managed_scaling {
maximum_scaling_step_size = 10000 # 1回のスケールアウトごとに起動される最大の台数
minimum_scaling_step_size = 1 # 1回のスケールアウトごとに起動される最小の台数
status = "ENABLED" #マネージドスケーリングを有効にする
target_capacity = 100 # ターゲットキャパシティ
instance_warmup_period = 300 # インスタンスのウォームアップ期間
}
}
}
# ECSクラスタの作成
module "ecs" {
source = "terraform-aws-modules/ecs/aws"
version = "3.4.0"
name = "test-ecs-cluster" # ECSクラスタ名
container_insights = true # Container Insightsを有効にする
capacity_providers = [aws_ecs_capacity_provider.prov.name] # 作成したキャパシティプロバイダを指定
default_capacity_provider_strategy = [{
capacity_provider = aws_ecs_capacity_provider.prov.name # デフォルトも作成したキャパシティプロバイダを指定
}]
}
# リージョン名
data "aws_region" "now" {}
#ECSタスク用ロググループの作成
resource "aws_cloudwatch_log_group" "log_ecstask_test" {
name = "/ecs/test-ecstask" # ロググループ名
retention_in_days = 1 # 保存期間(日)
}
## ECSタスク定義に使うコンテナ定義JSONの生成
### APコンテナ
module "test_ap_container" {
source = "cloudposse/ecs-container-definition/aws"
version = "0.58.1"
container_name = "ap" # コンテナ名
container_image = "amazonlinux:2" # コンテナイメージ
command = ["sh", "-c", "sleep 600"] # 実行コマンド
container_memory = 15488 # ハードメモリ制限(MiB)
container_memory_reservation = 15488 # ソフトメモリ制限(MiB)
container_cpu = 4064 # 予約するCPUユニット数
essential = true # 基本パラメータ。trueの場合は、このコンテナの失敗によりタスクが停止する。
links = ["xray-daemon"] # リンク設定
log_configuration = { # ログ出力設定
logDriver = "awslogs"
options = {
"awslogs-group" = "/ecs/test-ecstask"
"awslogs-region" = data.aws_region.now.name
"awslogs-stream-prefix" = "ecs"
}
secretOptions = null
}
map_environment = { # 環境変数設定
"AWS_XRAY_CONTEXT_MISSING" = "LOG_ERROR"
"AWS_XRAY_DAEMON_ADDRESS" = "xray-daemon:2000"
"AWS_XRAY_SDK_ENABLED" = true
}
resource_requirements = [ # GPUを使用するコンテナの場合は設定する
{
type = "GPU"
value = "1"
}
]
}
### xray-daemonコンテナ
module "test_xray_container" {
source = "cloudposse/ecs-container-definition/aws"
version = "0.58.1"
container_name = "xray-daemon" # コンテナ名
container_image = "amazon/aws-xray-daemon:3.3.2" # コンテナイメージ
container_memory = 256 # ハードメモリ制限(MiB)
container_memory_reservation = 256 # ソフトメモリ制限(MiB)
container_cpu = 32 # 予約するCPUユニット数
essential = false # 基本パラメータ
log_configuration = { # ログ出力設定
logDriver = "awslogs"
options = {
"awslogs-group" = "/ecs/test-ecstask"
"awslogs-region" = data.aws_region.now.name
"awslogs-stream-prefix" = "ecs"
}
secretOptions = null
}
port_mappings = [ # ポートマッピング設定
{
containerPort = 2000
hostPort = 0
protocol = "udp"
}
]
}
## ECSタスク定義
resource "aws_ecs_task_definition" "test" {
# 注意:applyを実行するたびに、常に新しいリビジョンに更新してしまうため、lifecycleで更新されないようにしている
# このタスク定義を更新したい場合のみ、lifecycle部分をコメントアウトすること
# https://github.com/hashicorp/terraform-provider-aws/issues/258
lifecycle {
ignore_changes = all
}
family = "test-ecstask" # ECSタスク名
container_definitions = jsonencode([ # ECSコンテナ定義JSONを設定
module.test_ap_container.json_map_object,
module.test_xray_container.json_map_object
])
task_role_arn = module.iam_assumable_role_ecstask.iam_role_arn # ECSタスクロールを指定
cpu = 4096 # タスクCPUユニット数
memory = 15744 # タスクメモリ(MiB)
requires_compatibilities = ["EC2"] # 互換性が必要な起動タイプ
network_mode = "bridge" # ネットワークモード
}
templates/user-data.shの内容は以下。
#!/bin/bash
echo ECS_CLUSTER=${cluster_name} >> /etc/ecs/ecs.config
上記コードでTerraformを実行すると、登録インスタンスが0台のECSクラスタができる。

※注意:初めてECSを利用するAWSアカウントでTerraformを実行すると、以下のエラーが発生する。
│ Error: error creating ECS Capacity Provider (test-ecs-cp): ClientException: ECS Service Linked Role does not exist. Please create a Service linked role for ECS and try again.
→ECSのサービスリンクロールが無いことが原因なので、ロールを作成してTerraformを再実行すればよい。
作成方法はAmazon ECS のサービスにリンクされたロールに記載されている。
もしTerraformでサービスリンクロールを作成したい場合は、以下で作成できる。
(参考:ECS初回構築時に自動作成されるIAMロール「AWSServiceRoleForECS」とTerraformでの予期せぬ挙動)
resource "aws_iam_service_linked_role" "ecs" {
aws_service_name = "ecs.amazonaws.com"
}
※補足:ECSタスク定義の設定内容について
- ECSタスクは、動作確認用に「sleep 600」を実行するだけのコンテナで構成されている。
- ECSタスク内処理のトレーシング情報をAWS X-RAYに送る検証にも使用する予定のため、「Amazon ECS での X-Ray デーモンの実行」を参考にxray-daemonを実行するコンテナもタスクに含めているが、クラスタのスケーリングとは無関係なので気にしなくて良い。
- 「Amazon ECS での GPU の使用」によると、
ECSタスクでGPUを利用するときは、タスク定義にGPU数を設定する必要がある。
g4dn.xlargeのGPU数は1なので、1を設定した。 - ECSインスタンスは、ECS最適化AMIから起動する。今回はGPUを使うので、「Amazon ECS に最適化された AMI」記載の「Amazon Linux 2 (GPU)」のAMIイメージを指定する。
- ECSタスク定義に1タスクが使用するメモリ・CPUを設定することができる。
この値によって、1台のECSインスタンスでいくつのタスクが起動できるかが決まる。
今回はスケールの挙動がわかりやすいように、1タスクが1インスタンスを占有させたい。
そのため、g4dn.xlarge(4vcpu・16GBメモリ)1台の使用できるリソースぎりぎりを設定する。 - ただし、システム用にメモリはある程度残しておく必要がある。タスクに割り当てられるリソースは、コンテナインスタンス メモリの表示のように確認できる。
g4dn.xlargeでECSインスタンスを作成して確認すると、メモリ16038MB・CPU4096ユニットを利用できることが確認できたため、これをタスクに設定することにした。 - また、今回は1タスクにメイン処理のコンテナ(ap)とX-RAY連携用のコンテナ(xray-daemon)があるため、それぞれが使用するCPU・メモリについても設定している。
xray-daemonコンテナに設定例にあるメモリ256MB・CPU32ユニットを割り当てて、それを差し引いたメモリ15488MB、CPU4064ユニットをapコンテナに設定した。 - タスクが利用するメモリ量は、タスク単位の設定とコンテナ単位の設定がある。
コンテナ単位で指定した場合はタスク単位の設定は必須ではないが、今回はタスク単位もコンテナ単位も設定した。
また、コンテナ単位の設定にはソフト制限とハード制限がある。ソフト制限の分がECSインスタンスに最低限確保され、必要に応じてハード制限に達するまでバーストする。 今回はソフト制限もハード制限も割り当てられる最大の値にした。 - CPUにもタスク単位指定とコンテナ単位指定がある。
タスク単位指定はタスクが使用するvcpu数を指定し、コンテナ単位の指定は複数コンテナがCPU利用で競合した場合の使用比率を指定するという違いがある。
動作確認
タスクの起動
作成したECSクラスタで、動作確認用タスクを複数起動してみて、クラスタがどのようにスケールするか確認する。
期待する動作は、タスクが同時起動されると必要な分のECSインスタンス数にスケールアウトし、タスクが終わったら0台にスケールインすること。
タスクは以下の内容で起動した。
- タスク起動時の設定
結果
最初はECSインスタンスが1台も存在しないので、全てのタスクがPROVISIONING状態となる。

少し待っていると、キャパシティプロバイダの「希望するサイズ」が0から2に変わり、「現在のサイズ」も0から2に変わった。

クラスタのインスタンスも2台にスケールアウトしている。

ECSインスタンスが2台になったため、2つのタスクの状態がPROVISIONING→PENDING→RUNNINGと遷移し、処理が開始した。

その後、キャパシティプロバイダの「希望するサイズ」、「現在のサイズ」が2から5に変わり、5つのタスクがRUNNING状態となった。

次に、キャパシティプロバイダの「希望するサイズ」、「現在のサイズ」が5から8に変わり、8つのタスクがRUNNING状態となった。

今回実行した処理は「sleep 600」を実行するものなので、600秒経過したタスクから終了していく。
タスクが終了しても、ECSインスタンスはすぐにはスケールインせず、以下のように残っている。
(「実行中のタスク」が0となっているインスタンス。)

その後も様子を見ていると、ECSインスタンスはタスク終了から約15分後に削除された。
最終的に、ECSクラスタはインスタンス0台にスケールインした。
時間と併せてまとめると、以下のようになる。
0台→8台と一気にスケールアウトするのではなく、段階的にスケールアウトした。
タスクの起動から実行開始までにはある程度のリードタイムがあることが分かる。
①タスクを8件同時起動
②ECSインスタンスが2台にスケールアウト(①から約3分後)
③ECSインスタンスが5台にスケールアウト(①から約5分後)
④ECSインスタンスが8台にスケールアウト(①から約12分後)
⑤各ECSインスタンスがスケールイン(各タスク終了から約15分後)
何が起きていたのか
前提知識
何が起きたか把握するためには、ECS クラスター Auto Scaling (CAS)の仕組みを理解する必要がある。
「Amazon ECS クラスターの Auto Scaling を深く探る 」によると、以下のような仕組みとなっている。
<ECS クラスター Auto Scaling (CAS)の仕組み>
- ECS クラスター Auto Scaling (CAS)は、EC2 Auto Scaling グループ (ASG) のインスタンス必要数を調整することで、ECSクラスタをスケールアウト/インする。
- CASは、CapacityProviderReservationというメトリクスが、キャパシティープロバイダのキャパシティターゲットの値に近づくよう、ASGのインスタンス必要数を調整する。
- CapacityProviderReservation メトリクスは以下の公式で算出される。
CapacityProviderReservation = M / N × 100
基本的には、Mは 「プロビジョニング中を含むタスクを起動するために、必要なコンテナインスタンスの数」、
Nは「現在起動中のコンテナインスタンスの数」である。 - そのため、キャパシティターゲットの値によって、CASは以下の挙動となる。
- ただし、この公式が当てはまらない特殊なケースがある。以下の2つ。
- M = 0 かつ N = 0 の場合(つまり、インスタンスが0台でタスクが起動されていない場合) →「CapacityProviderReservation = 100」とする。
- M > 0 かつ N = 0 の場合(つまり、インスタンスが0台のときにタスクが起動された場合) →「CapacityProviderReservation = 200」とする。 この場合M の値は 200 / 100 / 1 = 2 となるため、初回起動の際のコンテナインスタンス数は、実際の必要数とは無関係に2と設定される。 (ターゲットトラッキングスケーリングには、ゼロキャパシティからのスケーリングを行う際に用いる特殊例があり、N=1で計算をする)
考察
上記の仕組みを踏まえると、今回行った動作確認の場合は、以下のような動きになると想像できる。
①インスタンス数が0台でタスク数が8個の場合、特殊ケースである「M > 0 かつ N = 0 の場合」に該当する。
そのため「CapacityProviderReservation = 200」となり、インスタンス必要数は2台が設定され、2台にスケールアウトする。
②インスタンス数が2台、タスク数が8個となり、「CapacityProviderReservation = 8 / 2 × 100 = 400」となる。
ターゲットキャパシティは100にしているので、CapacityProviderReservationを100に下げるためには、インスタンスは8台必要になる。
そのため、インスタンス必要数が8台に設定され、8台にスケールアウトする。
③インスタンス数が8台、タスク数が8個となり、「CapacityProviderReservation = 8 / 8 × 100 = 100」となる。
ターゲットキャパシティの値(100)と一致するので、スケールアウト/インは行われない。
④終了するタスクが出てくると、インスタンスが余る状態となるため、CapacityProviderReservationの値が100を下回るようになる。
そのため、インスタンス必要数が減少し、スケールインが行われる。
しかし、実際には2台→5台→8台と段階的にスケールアウトが行われた。
また、スケールアウトが行われた時間帯のCapacityProviderReservationメトリクスをCloudWatchで確認すると、こちらも想定の動き(100→200→400→100)とは異なる。

この点について、AWSサポートに問合せたところ、以下の回答だった。
- CapacityProviderReservation メトリクスにおける指標は、あくまでも ASG のトリガーとして機能する。
- ECS が必要なコンテナインスタンス数として計算を行った設定値がそのまま ASG のスケールアウト時の起動数として反映されるわけではない。
ASG 内における必要なインスタンス数は、ターゲット追跡スケーリングポリシーにより、別途算出される。 - そのため、キャパシティプロバイダが必要数として計算している数と、1 回のスケールアウトにて起動される数は必ずしも一致しない。
→CapacityProviderReservation はASGによるスケールアウト/インの実行トリガーとなるだけで、実際の起動数は別の方法で算出されている。
そのためスケールアウト/インの台数を正確に予測することは難しいが、大まかな推測は可能。
タスク開始までのリードタイムを短縮する
ECSインスタンスの起動にある程度時間がかかること、スケールアウトが段階的に行われることから、
ECSタスクが全てRUNNING状態となるまでには、ある程度のリードタイムが発生する。
ECSインスタンスはタスク終了後も15分程度は残っているため、その間にプロビジョニングされたタスクはほぼリードタイム無く実行される。
しかし、断続的にタスクがプロビジョニングされる場合は、ECSインスタンスが0台に戻っているため、リードタイムが発生する。
このリードタイムは、以下の設定値を調整することである程度短縮することができる。
キャパシティプロバイダの「minimumScalingStepSize」
説明
1 回のスケールアウトごとに起動される最小の値。初期値は1。
例えば10に設定しておくと、タスクが1~10個起動された場合は10台のインスタンスが起動する。
その状態で11個目のタスクが起動されると、さらに10台のインスタンスが追加され、合計20台となる。
デフォルトの1だとスケール速度がタスク数増加に追いつかない場合に、数を増やすことを検討するとよい。
一方で、インスタンスが必要以上に起動し、無駄なコストが発生しがちになる。
Terraformでの設定箇所
aws_ecs_capacity_provider resourceの「minimum_scaling_step_size」の値。
※手動で設定する場合の注意
マネジメントコンソールからキャパシティプロバイダを作成するときには指定できない設定値のため、AWS CLIを使用して作成する。
minimumScalingStepSizeが10のキャパシティプロバイダを作成する場合の例は以下。
$ aws ecs create-capacity-provider --name test-cp --auto-scaling-group-provider autoScalingGroupArn="使用するASGのARN",managedScaling=\{status='ENABLED',targetCapacity=100,minimumScalingStepSize=10,maximumScalingStepSize=100\},managedTerminationProtection="ENABLED"
ASGの「最小キャパシティ」
説明
ASGが管理するインスタンスの最小台数(=常時起動させておくECSインスタンス台数)。
ここを0ではなく1以上にすることで、常に待機しているECSインスタンスを指定の台数用意することができる。
このECSインスタンスのリソースが空いていれば、起動されたタスクはほぼリードタイムなく開始される。
ECSインスタンスのリソースが埋まっている場合には、スケールアウトが発生し、やはりリードタイムが発生する。
常時起動するインスタンスがある分コストがかかるが、常時一定数のECSタスクが起動される見込みであれば、0台からスケールする場合と変わらない可能性もある。
Terraformでの設定箇所
autoscaling moduleの「min_size」の値。
キャパシティプロバイダの「ターゲットキャパシティ」
説明
前述したとおり、CASはCapacityProviderReservationの値を、この値に近づけようとする。
そのため100より小さい値にすれば、タスク数に対して余裕のあるインスタンス数が起動されることになる。
例えば、ターゲットキャパシティを50として8個のタスクを起動すると、
必要数の8台の2倍余裕がある16台のインスタンスが起動してくる。
常にECSインスタンス台数に余裕があるため、急激にタスク数が増えない限りは、ほぼリードタイムが発生しない。
しかし、インスタンス費用も多くかかることになるので、要件に合わせて値を調整する必要がある。
例えば、「常に1台だけ余分に起動していればよい」ということであれば、99にしておけば実現できる。
設定にあたっての注意
ASGの「最小キャパシティ」を0としているECSクラスタで、ターゲットキャパシティを100以外にすると、以下挙動となるため注意が必要。
ターゲットキャパシティに100以外の数字を設定した場合、スケールアウト/インのトリガーとなるCloudWattchアラームが以下のように設定される。
- スケールアウトのトリガー条件:1 分内の1データポイントのCapacityProviderReservation > ターゲットキャパシティ設定値 →ターゲットキャパシティが50の場合、「CapacityProviderReservation > 50」
- スケールインのトリガー条件:15 分内の15データポイントのCapacityProviderReservation < ターゲットキャパシティ設定値の9割の値 →ターゲットキャパシティが50の場合、「CapacityProviderReservation < 45」
タスクが0個の場合、ECSクラスタの状態は以下のように遷移する。
①M = 0 かつ N = 0 なので、「CapacityProviderReservation = 100」となる。
②スケールアウトのトリガー条件に引っかかり、ECSインスタンスは2台にスケールアウトする。
③M = 0 、N = 2であるため、「CapacityProviderReservation = 0 / 2 × 100 = 0」となる。
④スケールインのトリガー条件に引っかかり、ECSインスタンスは0台にスケールインする。
⑤M = 0 かつ N = 0 なので、「CapacityProviderReservation = 100」となる。
⑥以下繰り返し。

→タスクが0個のときは、約15分おきに2台のECSインスタンスの再作成が行われてしまう。
これにより、タスクが起動された際に、即座に実行できないタイミングが存在することになり、「常時余裕のあるインスタンス台数を維持する」という目的を達成できていない。
対策としては、ASGの「最小キャパシティ」に1以上の値を設定すればよい。
この場合以下のような遷移となり、スケールアウト/インがループすることを防止できる。
①M = 0 かつ N = 1 なので、「CapacityProviderReservation = 0 / 1 × 100 = 0」となる。
②スケールインのトリガー条件に引っかかるが、すでに最小台数である1台なので、これ以上スケールインはしない。
⑥②がずっと繰り返され、トリガー条件は満たし続けるが、スケールインしないためECSインスタンス台数は1台のままキープされる。

Terraformでの設定箇所
aws_ecs_capacity_provider resourceの「target_capacity」の値。
各設定値変更のユースケース
- タスク数のスパイクにスケールアウトが追いついていない場合は、キャパシティプロバイダの「minimumScalingStepSize」を増やすことを検討。
- ある程度の頻度で一定数のタスク起動が見込まれる場合は、ASGの「最小キャパシティ」を1以上にすることを検討。
- 常時リードタイム短縮したい場合は、キャパシティプロバイダの「ターゲットキャパシティ」を100未満にすることを検討。 その際はインスタンス再作成のループを防止するため、ASGの「最小キャパシティ」は1以上を設定すること。
- いずれもECSインスタンスの起動コストがかかる点は留意する必要がある。
まとめ
- CASを活用することで、0台からスケールアウトするECSクラスタ(EC2)をTerraformを使って構築できることを確認した。
これにより、LambdaやECS(Fargate)では実行出来なかった処理も、(厳密にはサーバはあるが)サーバレス的な実装ができる。 - タスク起動から実行までにある程度のリードタイムがある。設定値の調整で、ある程度の短縮は可能。
補足事項
- G系EC2インスタンスの実行中インスタンスの初期クォータはあまり多くない(自分のアカウントは64vcpuが上限だった)。
必要に応じて上限緩和申請を行う。 - プロビジョニング状態(タスクが起動されてからECSインスタンスに割り当てられるまで)でいられるECSタスク数の上限は100件。
上限緩和は出来ない。101件以降はタスクを起動してもエラーになる。
また、プロビジョニング状態のまま15 分経過したタスクは、実行されないまま停止されてしまう。
そのため、タスクの起動元で、タスクを登録する前にプロビジョニングタスク数が一定数以下であることを確認し、一定数を超えている場合は待機するなどの考慮が必要。
待機が頻発するような規模の場合は、ECSクラスタを複数個用意して、処理を分散させるなどの対応が必要。